October 7, 2022
Machine learning ain't Javascript


Machine Learning ain’t JavaScript!
Rant
Okay, this is a bit of a rant-post. I’ve been developing this library called torchwebio. Torchwebio aims to expose a PyTorch model as a web application. While building it, I was not-so-gently reminded of how many fragmented the ML ecosystem looks. It looks a lot like the state of Javascript frameworks in 2015. This post is less of an analysis of the ML ecosystem, and more of study of the different problems with fragmentation on different levels.
A small warning: I am a computer vision guy by trade, so most of this article is going to have computer vision bias. I try to be general, but my brain cheats me often.
Problem 1: The framework fragmentation problem
There are many, many ML frameworks. Back in 2017 when I quit my PhD., there were a handful : Theano, Caffe, Tensorflow, PyTorch. There was one metaframework - keras. There was one popular classic ML framework - scikit-learn.
| Deep learning | Classic Computer Vision | NLP | ML orchestration | ML deployment | Classic ML |
|---|---|---|---|---|---|
| Pytorch | OpenCV | NLTK | Dask | Onnx-runtime | scikit-learn |
| Tensorflow | scikit-image | Gensim | Ray | AWS Sagemaker Inference | XGboost |
| Transformers | BoofCV | CoreNLP | AWS Sagemaker Estimators/Jobs | Streamlit | Orange |
| Keras | SimpleCV | spaCy | Pytorch-lightning | seldon core | Shapely |
| Jax | kornia | TextBlob | Kubeflow | Tensorflow Serving | mlpack |
| Sonnet | Pattern | Spark | TorchServe | ||
| MxNet | PyNLPI | Airflow | KFServing | ||
| Gluon | polyglot | Dagster | |||
| DL4J | Prefect | ||||
| Chainer | |||||
| CNTK |
Find more here: https://github.com/EthicalML/awesome-production-machine-learning#model-serving-and-monitoring
The ML landscape is constantly expanding as people are thinking of ML systems increasingly more than just ML modelling. Don’t mistake me - it’s a good thing that we have so many ML frameworks. It shows that the community is lively and always innovating. However, the downside of this is that every framework wants to invent its own experience for the user - which means new interfaces, constructs, and ways of doing things.
This issue (or feature) has existed in the javascript world for a while. A quick look at https://dayssincelastjavascriptframework.com/ will tell you that a new framework is being invented everyday.
Do one thing and do it well
Instead of re-inventing the same wheel multiple, multiple times, its time for the community to take the unix philosophy of doing things. Doing one thing and doing it well roots from the early days of unix, to simplify the creation of UNIX. Instead of having a massive monolithic kernel, UNIX had a small kernel, but with helper tools. grep just works, cat just works, tail just works, time just works. It’s not being updated everyday, and to a large extent the code has remained relatively similar and stable for the last 50+ years.
Some ML frameworks are doing it right
Tensorflow isn’t. Tensorflow aims to “own” your ecosystem and experience and asks you to lock into the framework heavily. For example, Tensorflow lite, Tensorflow Extended, Tensorflow datasets all work with tensorflow. Don’t even try using these extended APIs with your non-tensorflow library. Pytorch takes a different approach; They promote an ecosystem of libraries and tooling that take a stab at the ecosystem. They let the community pick parts of the the ecosystem that they like. I have friends who pick their pre-trained model from huggingface’s dataset hub, apply some pytorch data augmentations go back to huggingface’s transformers and implement a pipeline and the model pushed to a custom model hub. Pytorch does many things, but does many things right - and that flexibility in the experience is what is beneficial in the long run.
Why is this even a problem?
The problem can only be explained with my own life experience. I was a web designer back in my university days, up until 2011. My world was HTML4, CSS2 and the good old JQuery. In the subsequent years, HTML5 became a thing, CSS3 happened, and nodejs took over. I wanted to make a website in 2015 and I did not know where to start! I had a tough time getting to know how JS can be used in the backend, why everything now needed to be “served” from localhost during dev. And then React, Angular - what was all that about? SCSS and SASS - I was having a headache.
Likewise, we want Machine learning to be easy to the new user, and the returning rusty user. We don’t want to alienate a community because of the surprising poverty of many choices. There shouldn’t be a researcher double thinking one’s contribution due to some framework choice. We noticed, for example the growth of Yolo ever since it was translated into pytorch from darknet. It took the community nearly 4 years to extend Yolo, only because it simply didn’t exist in their framework of choice. As a community we don’t want citations to be affected by our choice of frameworks.
Problem 2: Same ML problem, many interfaces
Have you heard of detectron2? Have you heard of Yolov5? Have you heard of SSD? All of these are amazing libraries in their own right, but they’re all solving the same problem - object detection. Each of them propose their own interface, API and way of doing things. “Why?” One might ask. And I’m asking the same.
The problem is that it’s not just the interfaces. The problem is deeper, way deeper.
Standardise datasets
There are datasets that for the same problem, and often have different annotation styles. Sometimes the difference is ever so slight, that one has to invariably build different parsers for different datasets.
For example, this is the diff between annotation schemas on the LVIS dataset and the famous COCO dataset.
annotation {
id: int,
image_id: int,
category_id: int,
segmentation: [polygon],
area: float,
bbox: [x,y,w,h],
+ iscrowd: bool
}
See how the iscrowd key sneaked in for the COCO dataset? That’s because COCO uses the same dataset for multiple problems. Instead of having an annotation schema on a per-problem basis, COCO tries to follow the same schema across different datasets within the COCO umbrella. In grand realm of object detection (or instance segmentation), LVIS and COC are still fairly similar. Look at something like Pascal VOC, which has a completely different and outdated XML based annotation.
<annotation>
<folder>vehicles</folder>
<filename>ff9435ee-ba7e-4d32-93bb-d931b3d2aca7.jpg</filename>
<path>E:\vehicles\ff9435ee-ba7e-4d32-93bb-d931b3d2aca7.jpg</path>
<size>
<width>800</width>
<height>598</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>truck</name>
<bndbox>
<xmin>7</xmin>
<ymin>119</ymin>
<xmax>630</xmax>
<ymax>468</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<bndbox>
<xmin>40</xmin>
<ymin>90</ymin>
<xmax>100</xmax>
<ymax>350</ymax>
</bndbox>
</object>
</annotation>
What does this imply? Libraries that parse instance segmentation dataset now have to have three parsers to load datasets in the same problem domain. This doesn’t have to be like this.
There is definitely a void here. Standardised annotations are clearly a need here, and there is a definite opportunity here to fill in the gap.
Interoperable configurations
Okay, so we load a dataset somehow, we then want to do something with this dataset. We want to train an ML model or fine-tune it, or some other of fancy task. Most of these frameworks have programmatic ways to implement a task. This is good, and fragmentation at this interface level is good. It’s even desirable to have more fragmentation in the “way of doing things” so the ecosystem can constantly re-think how best to “abstract” a problem.
However, many of these frameworks also provide a “configuration-file” way of running a task. This permits the user to run a task from the command line. Look at detectron2’s command to run inference on a single image.
python demo.py --config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \
--input input1.jpg input2.jpg \
[--other-options]
--opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl
And the corresponding configuration file looks like
_BASE_: "../Base-RCNN-FPN.yaml"
MODEL:
WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl"
MASK_ON: True
RESNETS:
DEPTH: 50
SOLVER:
STEPS: (210000, 250000)
MAX_ITER: 270000
Why does an inference step on a single image need to know about STEPS or MAX_ITER ? Why does it even matter? Why does the configuration have a _BASE_ configuration? What if you send this config over to a friend and forget the base configuration?
Detectron2 introduces a configuration language for the sake of it. The famous paper “Hidden Technical Debt in Machine Learning Systems” talks about Configuration debt, misleading every-framework-out-there to introduce a configuration language. What implementers often fail to realise is that many configuration standards is also a technical debt.
What should we do? We need foundation owned project to standardise configurations - which is flexible enough for different deep learning tasks, but also inflexible enough so implementations do not hijack and pollute it.
Receptive to the higher stack
What mid-level frameworks often fail to understand is that they are mid-level because frameworks exist below them and above them in the ML stack. These frameworks often benefit from quality of life improvements from frameworks upstream to these mid-level frameworks. They often overlook that there are other frameworks which consider these mid-level frameworks as upstream.
For example, consider a deployment library like Gradio or Streamlit. These are often used to “demo” your machine learning solution. Most of these libraries require you to spec out your UI. But why do we need to spec out our web application in its entirety, when they quite often fall into the same buckets of common problems? Gradio goes in the right direction but I fell like they have missed out the last layer of the puzzle. *Torchwebio, a library I’ve written tries to solve this issue by being very, very opinionated (and therefore alienating most of my users)*.
I’ve digressed. What these libraries end up doing is expose a machine learning solution to common machine learning problems. What these libraries would really really like is standardised definition to the problems. If the problems are standardised, their solutions also may be standardised.
What should we do? Just like to a common configuration language, we need a consumption layer that is inter-operable between different frameworks. The insertion of this “adaptive” layer will permit one line consumption of ML solutions, therefore simplifying everything for the layers above in the ML stack.
It’s okay to be opinionated
There are more problems with the ML ecosystem, but they aren’t relevant to my fundamental rant. A lot of machine learning libraries aim to be general, support many use cases, and therefore sacrifice on user experience.
There is no one-size-fits-all in this universe, and as a result of poor design, many of these frameworks suffer from leaky abstraction. Alienating users is a good thing; it shows the power of being opinionated. As there is less focus on the horizontal breadth of the stack, there is more focus on the vertical depth of the stack, permitting more and more high level applications and constructs to be built on top. Supporting the entire breadth of the ML stack is hard since the ML space is constantly evolving - Yesterday’s object detection problem has turned into today’s diffusion problem.
The only realistic way we can deal with a rapidly evolving ecosystem is to be opinionated, build a vertical stack, learn from our mistakes, tear it down, re-build new abstractions and repeat. However, if we keep waiting for “the perfect” abstraction, the stack doesn’t grow vertically and we never end up growing the solution space of real-world solutions.
How I dealt with this issue in torchwebio
Why?
So I wrote torchwebio, which is just a few lines of code, to solve a fundamental problem in ML training loops. Often, there is a distinct “training” pipeline and an “inference” pipeline. While I was reading about continuous learning, I kept thinking to myself - “Would it not be nice to use/deploy my model while it is being trained?” Can I truly affect my model’s training based
How?
My first thought was - “Oh! I could checkpoint my model and have a script run watchdog to look at my checkpoint folder and update an application based on a new checkpoint.” Something about that design felt off, it felt too circuitous. I didn’t want a separate “training” stage and a separate “inference” no matter how granular it was.
The next thought was to have it in the training loop itself. Oh! I was onto something. The same approach like the above watchdog approach, but instead of watching the model file, I try to watch the model data-structure in python itself. Something like
model = attach_deploy_hook(model)
# some training loop. Could also be event based.
for epoch_idx in range(epochs):
for batch in batch:
train_batch(..)
What?
So I had a plan of action. I new I wanted to plug into a training loop and “emit” an application. But which framework do I support? Did I have to write a crazy amount of code to support everything out there? Nope, not going to do that.
So I decided to stick to the pytorch ecosystem. I decided to keep things extremely simple, and write the least amount of code. So I identified standard libraries for my favourite ML problems. I used timm specifically because it gave me a very simple and standard way of accessing different models for image classification. This is what I meant earlier about fragmentation, the stack and being opinionated.
| Image Classification | pytorch-image-models (timm) |
| Object Detection | detectron2 |
| NLP | Huggingface |
And then I decided to just support these libraries. I honestly did not care about the rest of the ecosystem.
The result
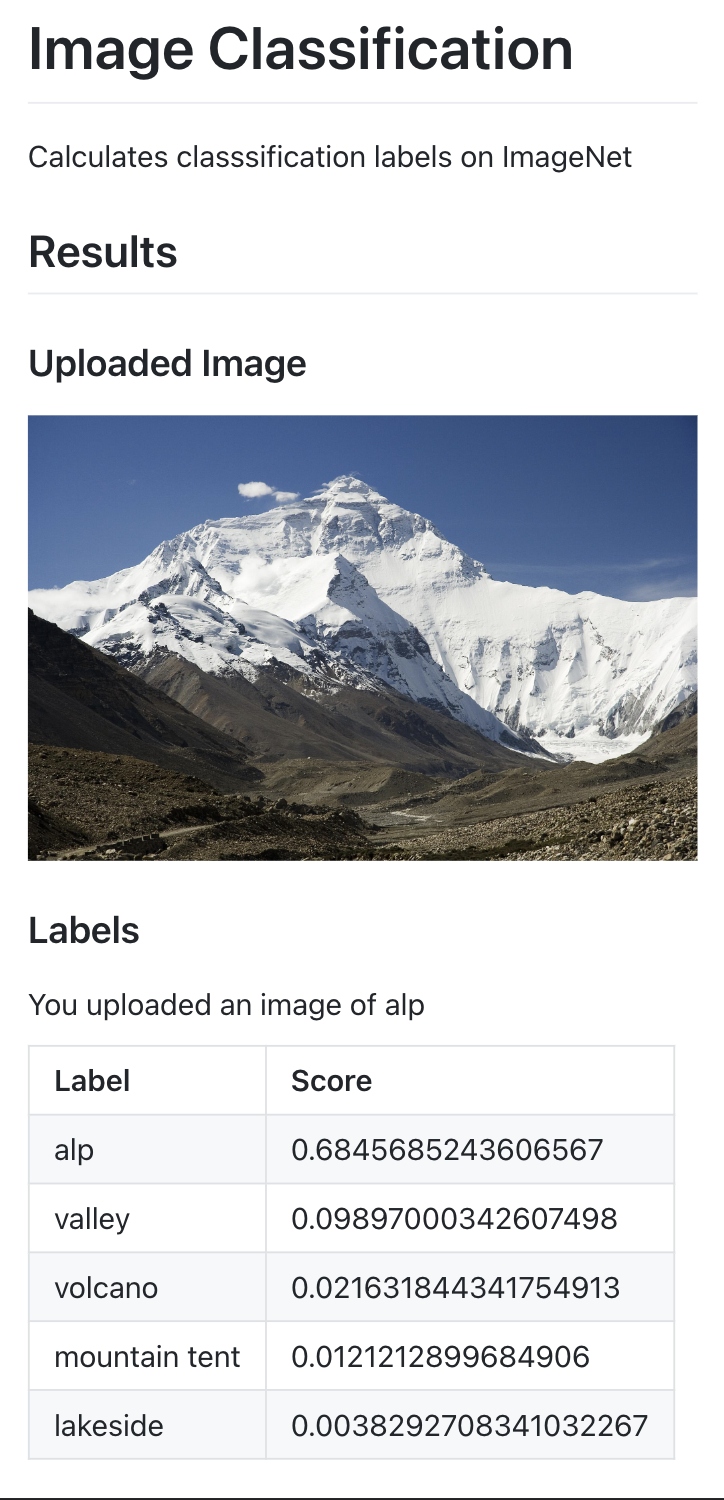
A very simple interface to generate web applications, that “just works” within my definition of the ecosystem.. .
import timm
from torchwebio.webalyzer import webalyzer
# Load a TIMM-like model or a regular pytorch model
model = timm.create_model('tf_efficientnet_b0_apss', pretrained=True)
# ....
# Fine tune the model
# ....
# Launch the web UI
webalyzer(model)
and Viola!