October 15, 2022
The Emergence of the full stack ML engineer


The Emergence of the full stack ML engineer
A bit of history
In the beginning was code (nice TED talk here).
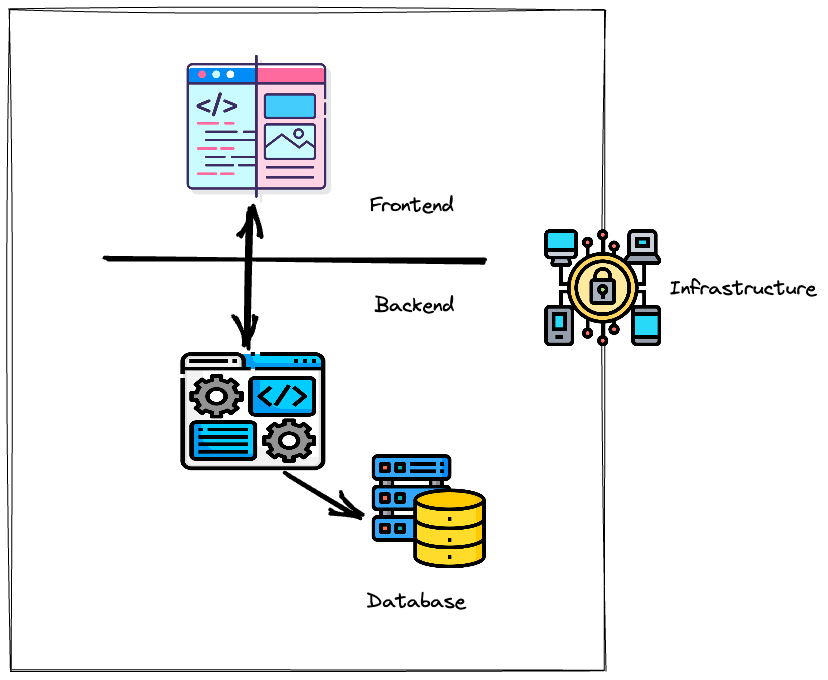
Way back in the 1980s, the client server programming paradigm came into being. This changed the then long-standing paradigm of a monolithic application or tool being served to users packaged with application logic. There was a now a need to decompose applications into “backend” logic and “frontend” logic.
Web development 0.0
Fast-forward to the late 1990s and the early 2000s, there was the rise of Web 1.0 and standards started emerging. The earliest websites were static websites, but we slowly start seeing the existence of dynamic web content with rich Javascript. Around this time, we see the earliest appearances of “The Stack” (such as the LAMP stack) - a suite of languages and paradigms serving different pieces of a website (such as databases, backend and frontend). Even though we had a full stack here, developers at this time were simply called Web Developers.
Slowly, we see the arrival of two-way communication and rich web content with collaboration - such as social networks, comments on blogs and tagging of information. These became emerging standards for Web 2.0, which ushered in a new generation of standards of HTML5, CSS3 and ever-growing Javascript standards. Now we’re in the late 2000s
Web applications
This surfaced a new kind of applications called Web Apps, which slowly started replacing desktop applications. With this, came different meanings to the stack such as - Ruby on Rails, Laravel, Python Django, LAMP, XAMPP and more! This meant there was more fragmentation in the ecosystem, but also several “communities” of developers.
This is when we had the unfolding of the Full Stack Developer. Instead of hiring different backend, front-end and database developers, organizations started focussing on hiring full-stack developers who had experience across the choice of the tech stack that the organization had built up. In the early days of Web 2.0, most web applications were just hosted on rented Linux boxes on a hosting service provider (like GoDaddy).
In parallel, two things happened - Javascript everywhere, and The cloud. We had the materialization of the “Javascript” stack. Javascript (NodeJS) on the backend, Javascript on the front-end. Simultaneously, AWS just blew up (The deceptively simple origins of AWS).
The full stack developer
The new full stack developer beyond 2015 started looking like this
- Can code a frontend using CSS3, HTML5 and Javascript
- Can code a backend using a NodeJS framework like Express or Meteor
- Can communicate with both relational and NoSQL databases
- Can spin up infrastructure to deploy a website using a cloud provider like AWS or more recently using a service like Vercel or Amplify or Netlify.
A little ML history
Lets laterally shift to talk about Machine Learning. Machine Learning, unlike popular knowledge, is old - it is a very old field, older than the web itself. It was coined in 1959 in a paper titled Some Studies in Machine Learning Using the Game of Checkers.
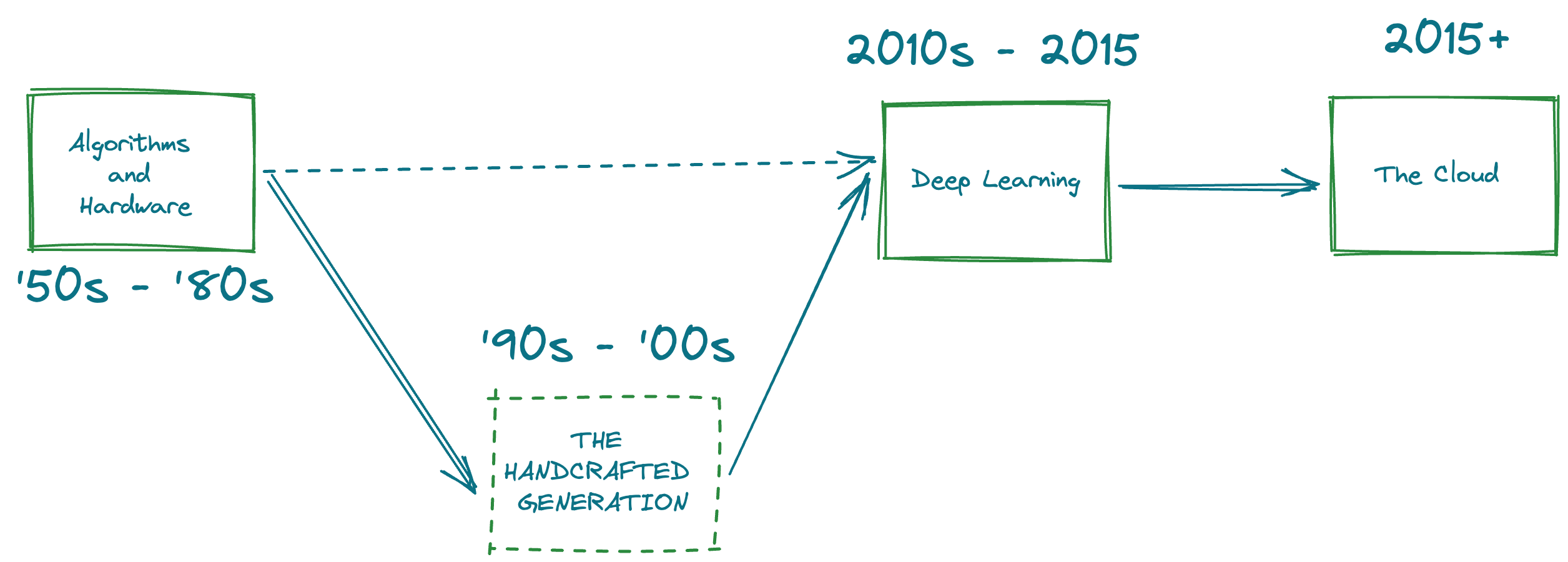
Phase 1: Algorithms and Hardware
The community made systematic strides forward - with the invention of the first neural network soon after in 1960, and that too in physical form. Since this was also around the birth of computing, most of the community was focussed on Algorithms, such as A* and breadth first search. The focus of this artificial intelligence phase was not on data, but instead to efficient solutions to known problems. Meanwhile, the “learn from data” paradigm was inching forward - with the creation of Backpropogation, which itself was borrowed from control theory (Gradient Theory of Optimal Flight Paths). This resulted in the creation of the first practical neural network - LeNet (Back propagation applied to handwritten zip code recognition). The neural network community continues to move, mostly laterally instead of forward, but albeit slowly because soon enough, they hit compute limits. ConvNets also suffered from AT&T breaking up (Yann LeCun’s rant on ConvNets being snatched away from him).
Phase 2: The Handcrafted generation
While the neural network slowed down, "machine learning" as a term started gaining popularity. The focus was to go back into fundamental statistics such as hyperplanes (SVM), Bayesian approaches, distributions and graphical models. What could not be achieved in an end to end system such as Neural networks, was now achieved by handcrafting features. Feature detection and extraction became common place words, with algorithms such as HOG, LBP, Sift and many more being published. A lot of emphasis was placed on “understanding data” and improving the amount of information that could be extracted from raw data. However, this approach was very man-made and handcrafted for specific purposes - and the extraction of information was not guided by the distribution of data. Proxy methods such as Bag of words materialized wherein many of these handcrafted features were extracted, and a clustering based mechanism acted as an adaptation to a given dataset. This phase also created a distinct separation between feature extraction phases and machine learning phases, and a distinct pipeline emerged. One drawback of this generation was that the machine learning algorithms did not scale with data. As the quantity of data being collected increased, these pipelines plateaued without being able to “absorb” large scale data.
In the background, Python was created in the early 90s, and went on to gain popularity in the late 2000s
Phase 3: Deep learning
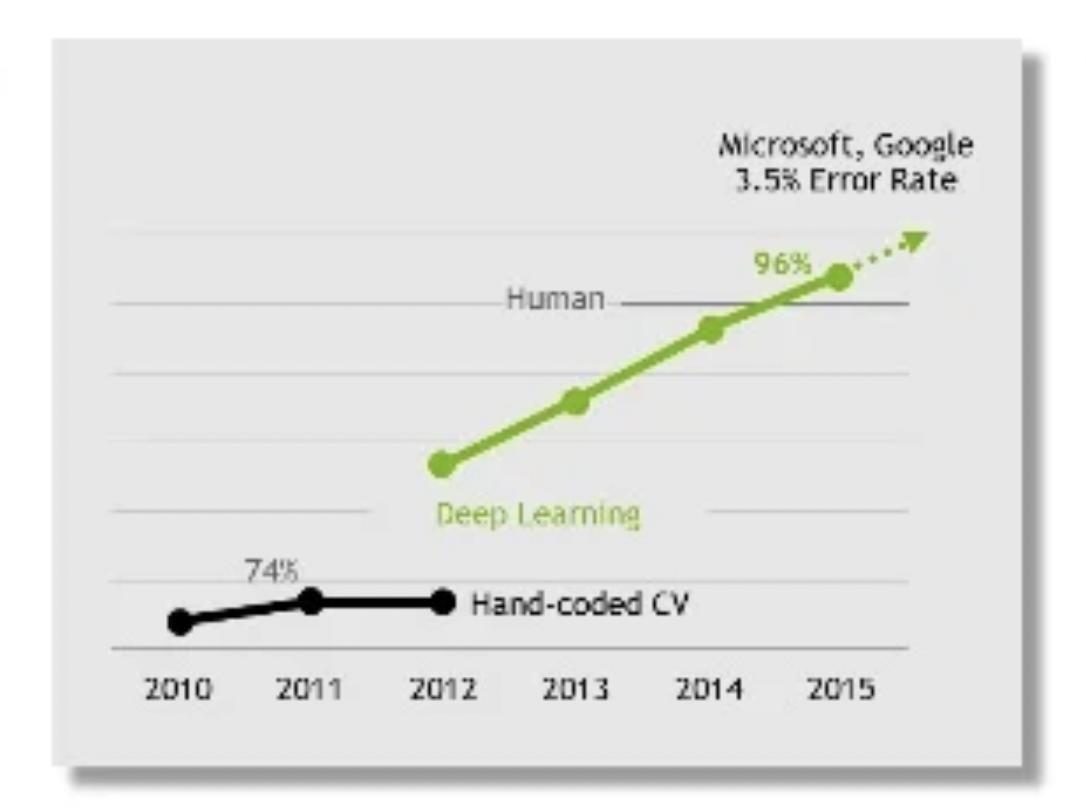
It all started in 2012. Three essential ingredients were in place. One - A large scale dataset was created by Fei-Fei Li and Co. called ImageNet in 2009. Two - ConvNet’s patent had lapsed in 2007, and future iterations of Convolutional networks could be invented permissibly. Three - Gaming really picked up with amazing games like Crysis and Skyrim requiring demanding GPU cards. What happened as a result was the organic combination of these raw materials. AlexNet came into being, which can essentially be summarized as follows - “Let’s take a convolutional network and make it deeper because now we have more compute, and let's train it on a supermassive dataset, because now we have ImageNet”. They achieved amazing results on ImageNet and ushered in a new generation - which took a while to pick up because of the cost of compute. What this new deep learning generation achieved was the ability to scale the performance of one’s model to large data.
In parallel, in the rest of the computing world, several things were happening
- Large amount of data was being collected by web applications like Google, Facebook, etc.
- The “cloud” started becoming a thing, and cloud-first businesses emerged.
- Moore’s law started flattening for CPUs, while GPUs were still getting faster.
- Python had become a de facto standard for machine learning with NumPy, Scikit Learn and Pandas being the first elements of the ML stack.
Phase 4: The cloud and now!
This new phase where we are right now is all about leveraging the cloud for incredible applications and machine learning models. This means that machine learning models had to be inherently distributable. This triggered the creation of frameworks such as Horovod and Spark, and PyTorch natively started supporting distributed training. These frameworks also meant that the fixed cost for new companies dramatically reduced while more of the cloud was adopted. Models that might have required 5 weeks to be trained on a big GPU now required just 1 day and ~50 GPUs. These constructs meant that the end to end training time for models dramatically reduced, which translated into more iterations of models in production. Paradigms such as Data-centric AI arose, which put the focus back on data and the movement of data. Likewise, cloud native machine learning frameworks were born - such as Sagemaker and Databricks.
A notable development started happening in deep learning research - where in Machine learning research was more active in companies than academia.
A Full stack ML engineer
Finally coming to the purpose of this blog post, that is the description of the full-stack-machine-learning person. As Machine learning evolved in tandem with large scale web infrastructure, Machine learning started leveraging the cloud and beyond. Likewise, since most of the machine learning today is happening in industry, a lot of practical machine learning is driven by product and therefore value generation. This also means that the end goal is not a research paper and hence the code that backs the machine learning model has to be optimized, maintainable, scalable and deployed as a product or into a product, creating the need of a skill level that is “full stack” in ML and well versed across the stack.
Tangentially, a lot of the machine learning is now happening on IOT devices (such as Alexa and Nest), which means that there is a need for a distinct optimization(or quantization) phase to make ML inference cheap and fast. As a product becomes more mature, and processes start becoming more fixed, data pipelines may be built to automate as many processes as possible.
The skill set
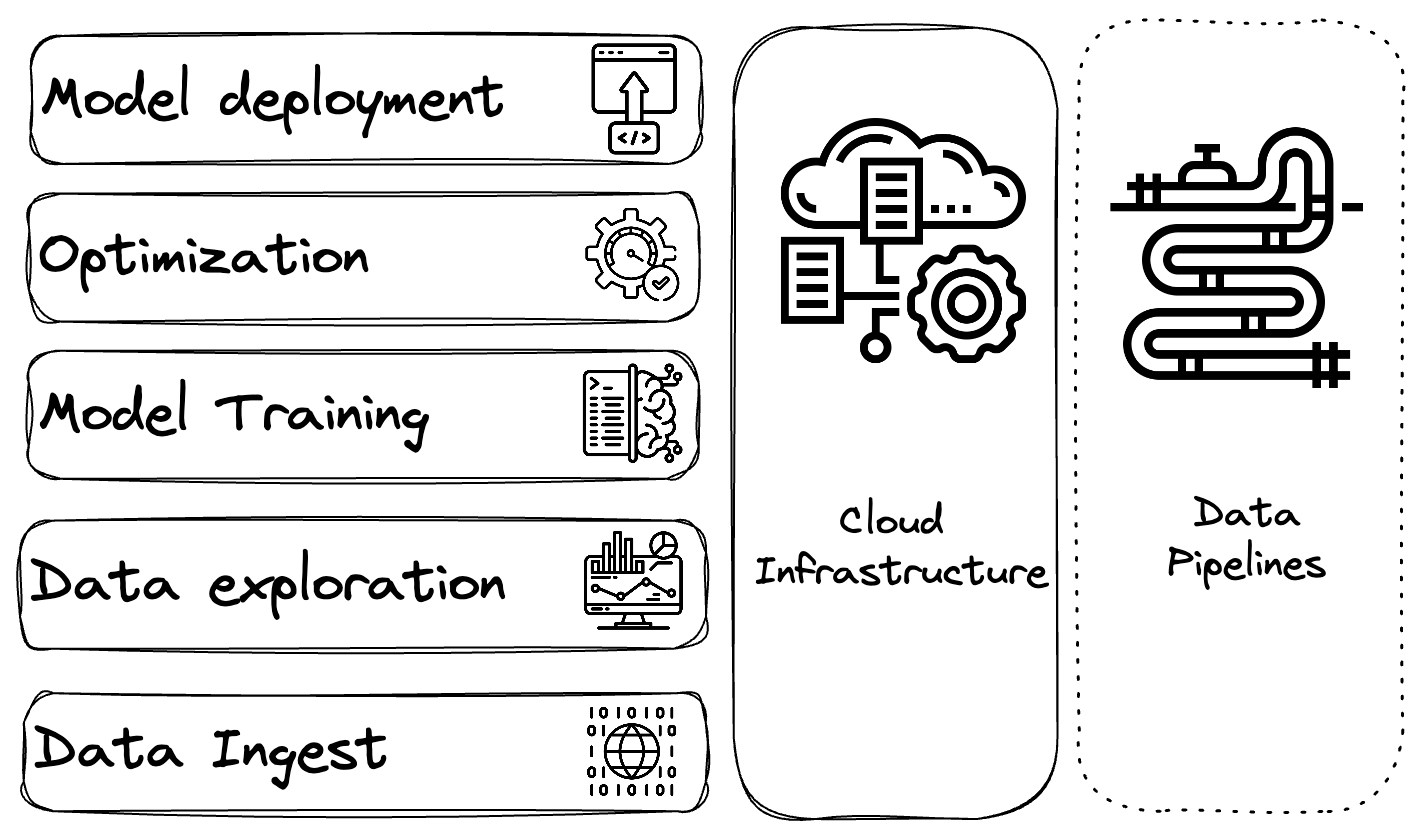
Today’s full stack ML engineer works across the stack, and can work from ideation all the way till deployment. In today’s complex cloud infrastructure world, this means getting down and dirty with the cloud and distributed compute. Let me walk you through the layers (libraries/frameworks linked are representative examples)
- Data ingest: Nothing happens without data. In order to ingest large amounts of data across different silos and warehouses, one has to write queries in different forms. This might mean using something like AWS glue or AWS Aurora or Parquet or BigData or Snowflake (amongst the popular many that exist). The whole objective in this layer of the stack is to curate unstructured, often distributed data into ML-ready datasets.
- Data Exploration: Once the data is curated into a structured format, it’s time to move on to the next step - Data exploration. Exploratory data analysis is a common step that guides the selection of models to train or fine tune. Another kind of data analysis is model dependent, and it involves using a trained model to observe how it views your data - using methods such as tSNE and UMAP. This might involve using libraries such as AWS wrangler, EDA tooling, whylogs or dask for lazy loading (amongst many out there). The objective in this layer is to understand the sanity of your dataset and get statistics to drive intuition for the ML modelling stage.
- Model training: If we have reached this stage it means that we have data in an organized format, and we have some insights from data with which we’ve built up some intuition. We might create a model using PyTorch or Tensorflow or Scikit learn. We might then train such a model either using the very same framework or higher level frameworks such as PyTorch lightning. Quite possibly, the training of these models will now happen on the cloud, which means some knowledge of infrastructure - using AWS EC2 and S3 with secure networking with VPCs, which might need some terraform to maintain some sanity. Thankfully, the cloud providers have come together to provide a lot of this infrastructure as IaC neatly packaged for AI purposes, with the emergence of AWS Sagemaker and Vertex AI and the likes of meta cloud providers such as Algorithmia. This objective in this layer is to train a ML model, possibly in a distributed fashion, while recording training and evaluation metrics.
- Model Optimization: Typically machine learning models that are trained carry a lot of bloat. ML techniques such as Knowledge distillation, Pruning and Quantization come into play to minimize the amount of memory and compute taken up by models. If a given model is going to be used only for inference, further assumptions can be made to aid in optimization. This might happen using the native ML framework or frameworks such as TVM that aid in the process post-training. Alternatively, there are cloud services/resources that aid in optimization such as AWS inferentia and AWS Sagemaker Neo. The objective in this layer is to optimize the machine learning model for the target device and purpose.
- Model Deployment: This is typically the last stage in the model release process, where in the model has to be deployed into a cloud application, as an API or into a device. In order to make this process seamless and straightforward, knowledge about the target system is useful. If the target application is cloud based - this might involve the use of Load Balancers, API gateways, VPCs and some kind of authentication if needed, quite possibly coded with Terraform. This might also mean wrapping the model inference in an API using a library like FastAPI and packaged as a docker image pushed to a registry. One might also use services like Sagemaker to do the above, which might be easy if one is using the same stack throughout the development process. Additionally, monitoring infrastructure might need to be set up - using Grafana, whylogs and Prometheus. Releasing to a device (IOT/edge/PC) might be a complete tangential task. Once the model is quantized (quite often a necessary precondition), the model inference quite often has to be manually coded up in an optimized language like C++. This might involve the usage of libraries such as ONNXRuntime, TensorRT, Metal, ArmNN or Tensorflow Lite. Releasing to devices is often done because there are constraints that prevent network access - perhaps due to GDPR for a given application or due to being a part of desktop stack (such as vscode intellicode or Siri). The very nature of these applications mean that network isolation has to be carefully designed or managed, with end-point protection skills. The objective in this layer is to release the model into a target infrastructure in order to produce value.
- Cloud Infrastructure is a broad skill that is covered across the stack
- Data Pipelines is a newer construct that has arisen from the data centric AI paradigm. If you’re just starting out building your product and the value of AI in your product has not yet been validated, forget about data pipelines. Once your product is mature, or you are building for scalability from the outset, it is useful to map the flow of data across the training and deployment process. The assumption in data centric AI is that the first model that is released is going to be far from suboptimal. The improvement of the model comes from monitoring the model in production, obtaining insights and data automatically, which triggers a re-training and re-deployment of the model. The objective of this paradigm is to minimize the amount of human effort across the release process.
tl;dr skill set
replace X library/framework/language by your-favourite-alternative
- Python
- PyTorch
- Sagemaker Python SDK
- Terraform
- Sagemaker model registry and inference
- Sagemaker Neo
- FastAPI
- Docker
- ONNX runtime
- Apache Airflow
- AWS S3
- Knowledge distillation
- Pruning
- Quantization
- Profiling
- Data distributions
- Outlier detection