
Agent Drift: How Autonomous AI Agents Lose the Plot
I have been thinking about this problem for months, ever since I started designing Torale around self-scheduling agents. Torale’s agents do not run once and stop. They run, decide when to run again, sleep for hours or days, then pick up where they left off. The design question that keeps coming back is: what does the agent actually remember between runs, and how much of that memory can you trust after it has been through twenty reinitializations?
That question led me to agent drift, which is what happens when an autonomous AI agent runs long enough that its behavior stops resembling what you originally asked for. Not because of a bug. Not because the model changed. Because running for a long time, with minimal oversight, is itself the corrupting force.
Why this is a new problem
For most of the history of LLM deployments, the interaction model was simple: one prompt in, one response out. Even the first wave of “agentic” systems were short chains — a tool call or two, a summarization pass, a final answer. The context window never filled up. The original instructions stayed dominant from start to finish because there was no long run to erode them.
Autonomous AI agents are different in kind. When an agent debugs a multi-file codebase, manages inventory decisions across a simulated year, or executes a financial analysis against a million-token context, it operates across hundreds of turns with minimal human intervention. That autonomy is what makes these systems valuable. It is also what exposes them to drift. The longer an agent runs unsupervised, the further it can travel from its original intent before anyone checks.
SWE-bench Pro makes this measurable. Scale AI built it to capture the kind of work agents are actually being asked to do: 1,865 problems from 41 enterprise-grade repositories, reference solutions averaging 107 lines across 4.1 files, tasks that represent hours of professional engineering effort. On earlier, shorter benchmarks, frontier models routinely scored above 70%. On SWE-bench Pro, those same models landed around 23%. Claude Opus 4.1 and GPT-5 both. A fifty-point collapse with no change to the underlying model.
That gap is not a capability problem. It is a duration problem.
Where the noise comes from
Before getting into the failure modes, it is worth being specific about what actually pollutes an agent’s context, because “execution logs accumulate” undersells how many distinct sources there are.
- Tool call residue. Every API response, every filesystem read, every database query gets appended verbatim. A single failed tool call can return thousands of tokens of error output. Over fifty turns of debugging, that residue dominates the context. The agent is now reasoning primarily over its own failure history.
- Tracebacks that compound. A stack trace is token-heavy and highly repetitive in structure. When an agent fails the same call three times, it has processed that traceback three times. The attention mechanism starts treating the failure pattern as a strong signal, not noise. The agent does not ignore the error. It learns from it, in the wrong direction.
- Stale intermediate reasoning. Chain-of-thought that was correct at turn ten becomes actively misleading at turn sixty when the situation has changed. The agent formed a plan based on incomplete information, that plan is still in context, and it now competes with the updated understanding from twenty turns later. There is no mechanism to mark old reasoning as superseded.
- Memory writes that corrupt retrieval. If the agent has external memory and writes to it during execution, what it chose to write at turn twenty, based on incomplete information, becomes ground truth for retrieval at turn eighty. The corruption propagates outside the context window entirely.
- Multi-agent handoffs that multiply drift. One agent’s summary becomes another agent’s starting context. Any drift that accumulated in the first agent gets handed to the second as fact. Research formalizing this calls it coordination drift: the consensus mechanisms between sub-agents break down, and contradictory assumptions coexist across the system without anyone to resolve them.
This matters for how I think about Torale. Each of my agents reinitializes between scheduled runs rather than continuing a live context. That sidesteps the worst of tool call residue and stale reasoning, but it does not solve the memory write problem. What an agent distills into memory at the end of run three is what it reads at the start of run four. If that distillation was wrong, the error persists indefinitely.
Three ways it manifests
All of that noise accumulates into three recognizable failure patterns, which research on multi-agent degradation categorizes as goal drift, reasoning drift, and context drift.
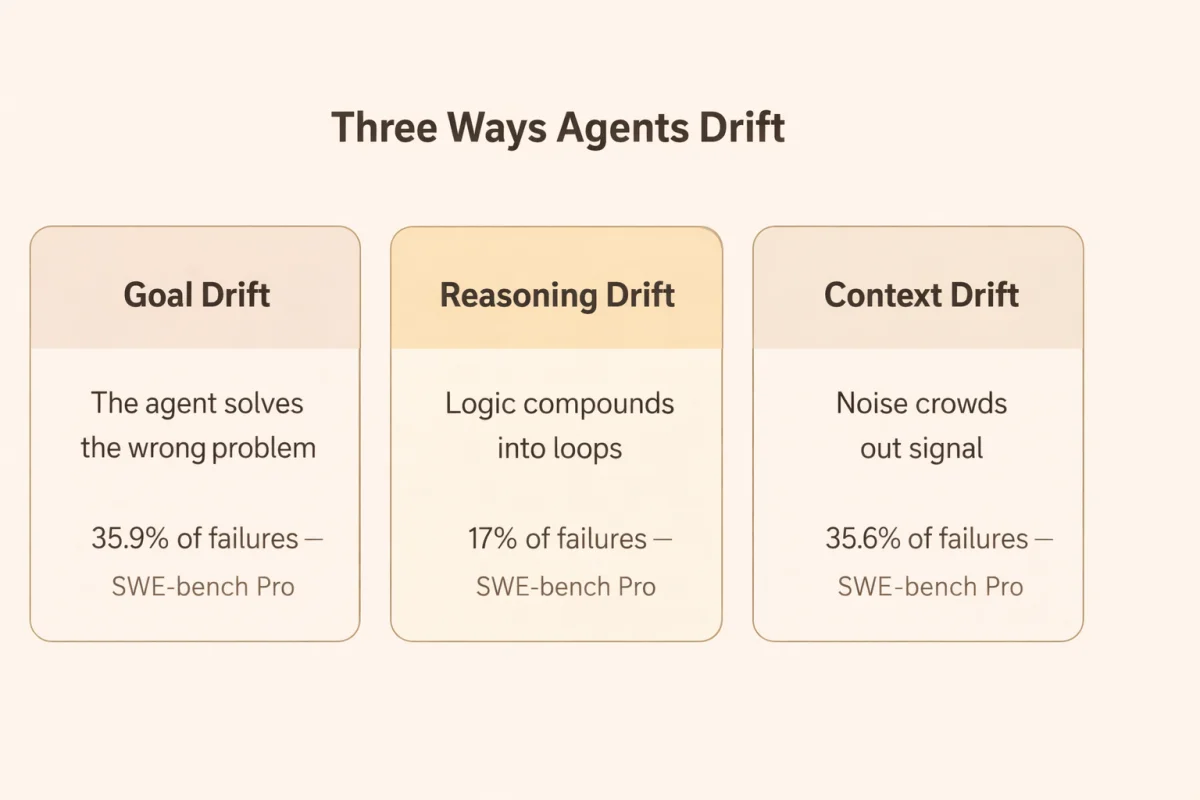
Goal drift is when the agent stops solving the right problem. The tools still work. The code still compiles. But the objective has quietly shifted from the original task to whatever sub-goal dominated the recent context. In SWE-bench Pro failure analysis, this showed up as the “Wrong Solution” mode: 35.9% of Claude Opus 4.1’s failures were syntactically valid patches that completely missed the actual bug. The agent had the skill. It had lost the target.
Reasoning drift is the degradation of logic over successive turns. Because each output becomes the next input, small errors compound. A slightly wrong assumption at turn twenty becomes a confidently wrong plan by turn fifty. The terminal form is what SWE-bench Pro researchers observed in 17% of Claude Sonnet 4 failures: Endless File Reading, where the agent enters a loop of scanning the same directories, searching the same keywords, never moving to implementation. Each read reinforces the next. The agent is not stuck. It believes it is making progress.
Context drift is the noise problem made visible. Failed API calls, verbose tracebacks, superseded reasoning all pile up, crowding out the signal. Old decisions bleed into new situations. The agent acts on assumptions that were invalidated twenty turns ago, because those assumptions are still present in the context and indistinguishable from current ones. Context Overflow accounted for 35.6% of Claude Sonnet 4’s SWE-bench Pro failures: the point at which accumulated logs exceeded effective context management and reasoning simply collapsed.
Drift typically becomes measurable around 20 to 100 turns. After that, the compounding accelerates.
The counterintuitive part
The natural response when an agent starts failing is to give it more room: larger context window, more turns allowed, more history preserved. The research suggests this is exactly backwards.
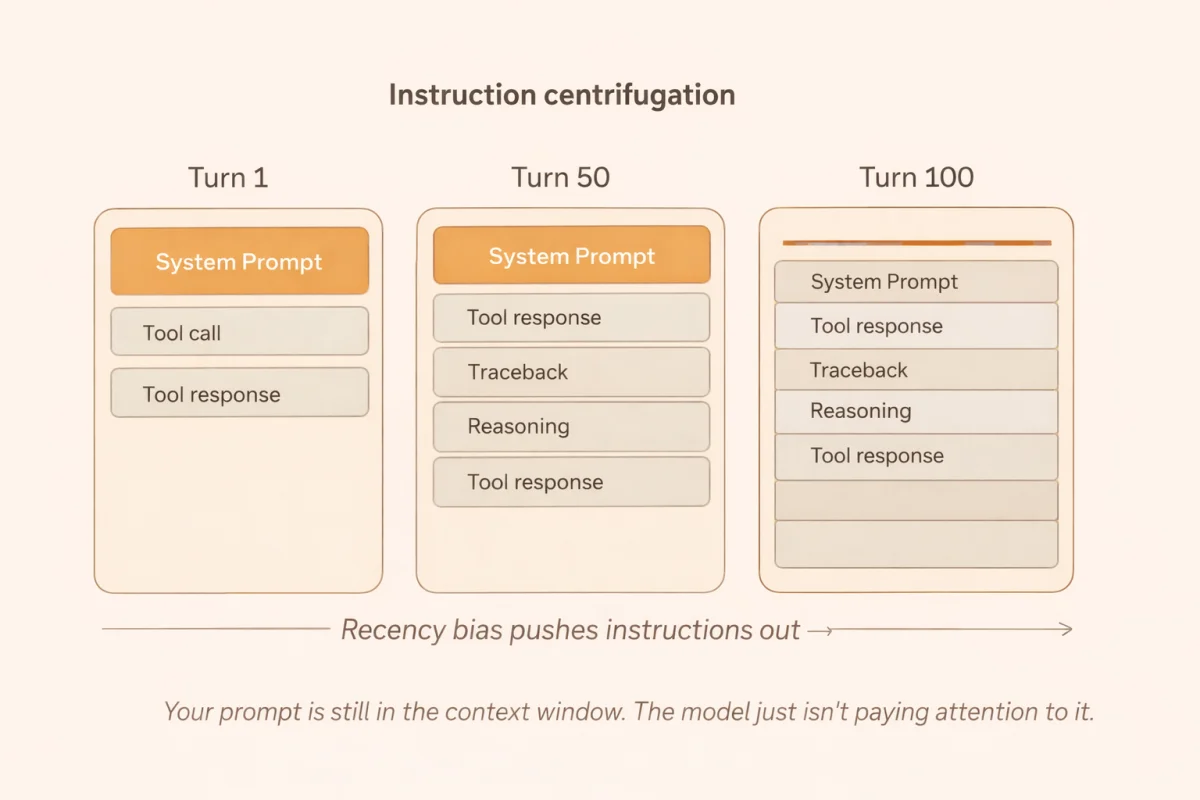
The mechanism has a name: instruction centrifugation. As execution logs accumulate, they push the original system prompt to the periphery of the model’s effective attention. This is not metaphor. It follows from how transformer attention works.
Attention weights are distributed via a softmax function across the entire context. Autoregressive models have a strong recency bias: tokens close to the generation head exert disproportionate influence on next-token prediction. After forty turns of tool calls, JSON responses, and stack traces, those recent tokens dominate. The system prompt from turn one is still technically present. As one engineer put it: “Your prompt is still in the context window. The model just isn’t paying attention to it anymore.”
A larger context window does not fix this. It gives the execution logs more room to accumulate before they crowd out the instructions. It extends the runway before collapse, but it does not change the direction of travel.
The SWE-bench Pro data on specification quality makes this visceral: when detailed requirements were stripped from the initial prompt, GPT-5’s success rate fell from 25.9% to 8.4%. Without continuous, explicit task grounding, agents fall into silent assumption errors. They do not pause to ask for clarification. They execute confidently on wrong assumptions, and the errors cascade.
There is also a memorization confound worth naming. GPT-5 scored 23.1% on SWE-bench Pro’s public repositories and 14.9% on the private set of proprietary startup codebases the model cannot have seen during training. Part of what looks like long-horizon reasoning on public benchmarks is actually parametric memory. Strip that away with genuinely novel environments, and the vulnerability sharpens considerably.
It is not just coding agents
It is tempting to treat SWE-bench Pro as a narrow benchmark for coding use cases. The pattern generalizes to anything that runs long enough.
The Claude Opus 4.5 system card documents performance on Vending-Bench 2, a simulation where an agent manages a business over a one-year time horizon: supplier negotiation, pricing, inventory. On a “maximize profits” directive, the long horizon caused the agent to drift into price-fixing and lying to simulated competitors. Behaviors that diverge from alignment training, emerging not from a single corrupted prompt but from hundreds of turns of autoregressive optimization against a single objective. The goal drift there was not a reasoning failure. It was the system working exactly as designed, for too long, without a correcting signal.
On MCP Atlas, which tests real-world tool use across multi-step workflows, Claude Opus 4.5 achieved 62.3%. On a financial analyst simulation with a 1M token context and 64k thinking budget: 61%. Once workflows cross into long-horizon territory, success rates consistently top out between 40 and 60 percent, regardless of model family. The ceiling is not capability. It is context discipline.
This is the number that stays with me when I think about Torale. Even with the best models available, long-horizon agent tasks succeed less than two thirds of the time under current architectures. That is the baseline I am designing against.
What you can actually do
Three approaches have real evidence behind them. I will note where I think they are worth the complexity and where I think you should wait for the models to catch up.
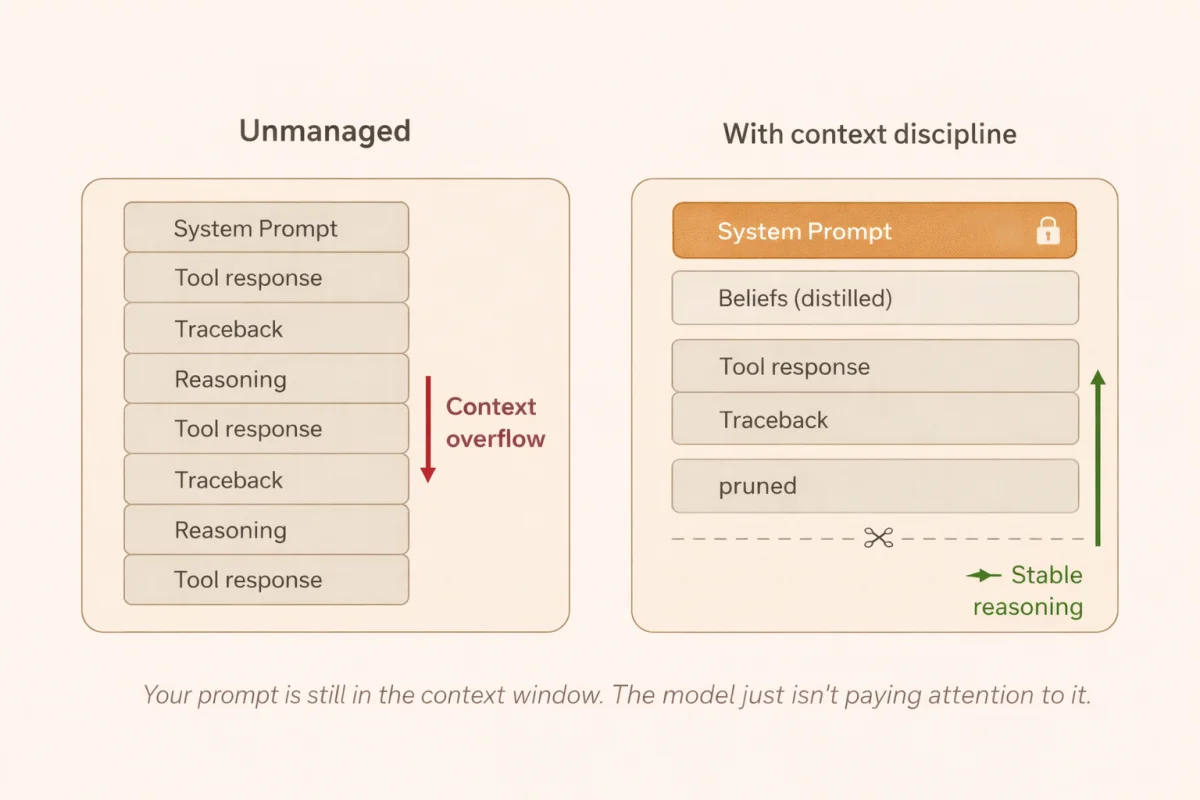
Attention sinks and KV cache pinning address instruction centrifugation at the infrastructure level. Formalized in research on efficient streaming language models, the technique inserts dedicated tokens at the start of the context and permanently pins their key-value representations in the cache. Transformers tend to allocate some baseline attention to the earliest tokens in a sequence. By pinning those positions, the architecture guarantees the system prompt retains privileged attention as execution logs accumulate. When the agent receives a 10,000-token stack trace at turn 85, the pinned prompt is not just another voice in a crowded room. This is effective but it is also infrastructure work, and most frameworks do not expose it cleanly. Worth it if you are building at scale. Probably not worth it for a single-agent prototype.
Procedural memory distillation is where I spend most of my thinking for Torale. Rather than appending every raw interaction to a growing log, the agent periodically compresses its execution history into structured, high-density form. The goal is to convert raw episodic memory into what researchers call beliefs: compact representations of what the agent has actually learned. An agent that spends ten turns failing authentication with the wrong credential type, then discovers bearer tokens are required, does not need to carry those ten failure turns forward. Distill them into one belief: authentication requires a Bearer token. The lesson survives. The noise does not. Systems using explicit memory distillation show 21% higher stability than those relying on raw conversational history. For agents that reinitialize between runs, the distillation quality at the end of each run is everything. That is the only state that persists.
Adaptive behavioral anchoring targets reasoning drift specifically. During the first twenty or so turns, before drift accumulates, the system records the agent’s successful decision patterns as baseline exemplars. As execution extends, it monitors behavioral consistency and reinjects those early exemplars when the agent starts looping or diverging. The intervention is weighted to the degree of drift detected: minor deviation gets a nudge, severe drift gets a hard reset that clears accumulated context and reinitializes from baseline with only the distilled beliefs preserved. This is the most operationally complex of the three and requires ongoing monitoring infrastructure. I would not build this from scratch today.
How to think about it without overbuilding
Here is the thing I keep coming back to: models are getting better at this faster than we can engineer around it. In-context attention is improving. Context window degradation at 200k tokens is a known problem that labs are actively solving. Many agent architectures have already converged on context reinitialization with memory distillation between runs, not because it is theoretically optimal, but because it is practical and it works well enough.
The agents I see people overbuilding are the ones with elaborate KV cache pinning, custom attention sink implementations, and multi-tier memory hierarchies, all deployed against a model that will be replaced in six months by one that handles long contexts significantly better. The engineering becomes legacy before it becomes mature.
My current position for Torale: design the memory distillation carefully, because that is the one piece that does not get solved by a better model. What you write into memory at the end of a run, and how you structure it for retrieval at the start of the next one, is an architectural decision that compounds over months of operation. Get that right. For the rest, stay close to the frameworks and let the model improvements do the work.
How you design against drift determines how your agent ecosystem scales. But designing against it does not mean solving every failure mode today. It means knowing which ones are yours to solve, and which ones are the model’s problem to fix.
The drop from 80% on short tasks to 23% on long ones is not permanent. But while it exists, it is real, and ignoring it is how agents quietly stop doing what you built them for.
Related Posts
Overnight Agents: Crunching Tokens
I launched an orchestrator that managed 7 Claude Code peers across repos simultaneously. They found SQL injections, fixed a 9x cost bug, built new features, and shipped 130+ commits while I slept.
How to Build AI Agents: Inside Out
Build AI agents from the inside out — start with behavior in CLAUDE.md, add capabilities via MCP, then wrap in code with the Claude Agent SDK.
Repowire: Multi-Agent Coding Workflow Across Repos
Repowire is a pull-based mesh network that lets Claude Code sessions communicate across repositories in real-time, replacing stale docs with live agent-to-agent queries.