
AI Agent Memory Management With Databases
Every time I build an agent, I end up solving the same problems I solved building backend systems a decade ago. Persistent state. Retries. Idempotency. Checkpointing. The LLM is new, but the infrastructure around it? That’s just databases and workflow engines wearing a trench coat.
This isn’t a metaphor. It’s literally what’s happening under the hood.
The Memory Problem
LLMs are stateless. You send a prompt, get a response, and the model forgets everything. Context windows help, but they’re finite and expensive. An agent that can’t remember what it did five minutes ago isn’t very useful.
So we give agents memory. And the moment you do that, you’ve created a database.
Think about it: the agent writes facts to memory, reads them back later, and uses them to make decisions. That’s CRUD operations. The agent’s memory is “a live, continuously updated database of things it believes about the world” (InfoWorld).
Most agent frameworks ship with some kind of memory store: vector DBs, JSON files, Redis caches. But these are often treated as afterthoughts. No schema. No access control. No audit logs. No backup strategy.
We need to start treating [agent memory] as a database — and not just any database, but likely the most dangerous (and potentially powerful) one you own. — Matt Asay, InfoWorld
If your agent can write to its own memory, and that memory influences future actions, you have a self-modifying system with persistence. That demands the same rigor as any production database.
Agents Are Workflow Engines
Beyond memory, agents execute sequences of steps. Plan. Execute tool. Check result. Decide next action. Repeat.
That’s a workflow. Some have argued that “agents are just workflow orchestration in disguise,” and they’re right. An agent doesn’t magically solve problems from first principles every time. It strings together known operations in a logical order.
Here’s a concrete example, a data analysis agent workflow:
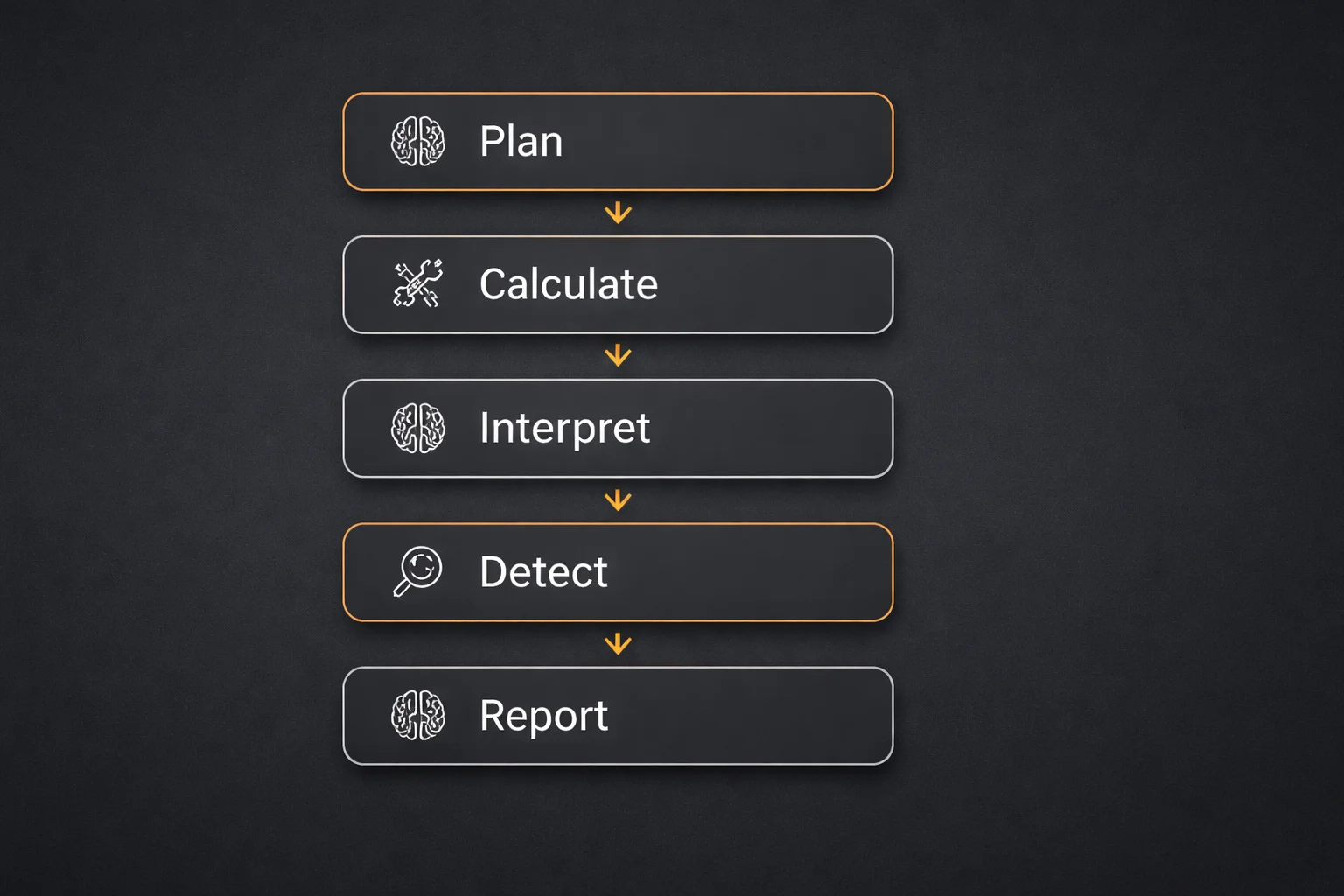
Each step depends on the previous. This is a DAG. It’s what Airflow, Prefect, and Temporal were built for.
The problem? If step 4 fails, a naive agent restarts from step 1. You re-run two LLM calls you already paid for. The model might phrase things differently this time, creating inconsistencies. This is expensive and fragile.
Why This Matters: The Retry Problem
In distributed systems, we learned that retries are dangerous without idempotency. If you retry “send email” and it partially succeeded, now you’ve sent two emails.
Agents have the same problem. If an agent step is “update customer record” and you retry after a network blip, you might double-update or corrupt state.
The solutions are the same ones we’ve used for decades:
- Idempotency keys: each action gets a unique ID; external systems ignore duplicates
- Checkpointing: save intermediate state so you can resume, not restart
- Transactional semantics: either a step fully succeeds or it’s rolled back

Modern agent frameworks are starting to build these in. Pydantic AI + Prefect caches task results automatically. If step 4 fails, steps 1-3 don’t re-run. Pydantic AI + Temporal wraps agent logic in durable workflows where the history is persisted and replayed on failure.
Durable Agents in Practice
I’m using Pydantic AI for these examples because it’s become my go-to agent framework. It’s refreshingly simple: just Python, type hints, and decorators. No DSLs, no YAML configs, no magic. Other frameworks like LangChain or LlamaIndex can probably achieve similar durability patterns, but Pydantic AI’s minimal surface area makes it easy to wrap with orchestration tools.
Let me show you what this looks like in practice.
The Naive Way (Don’t Do This)
# naive_agent.py - No durability, no checkpoints
from openai import OpenAI
client = OpenAI()
def analyze_data(dataset: dict) -> str:
# Step 1: Plan (LLM call #1)
plan = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Plan analysis for {dataset}"}]
).choices[0].message.content
# Step 2: Calculate statistics
stats = calculate_statistics(dataset)
# Step 3: Interpret (LLM call #2)
interpretation = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Following plan: {plan}\nInterpret: {stats}"}]
).choices[0].message.content
# Step 4: Detect anomalies - IF THIS FAILS, WE RESTART FROM STEP 1
anomalies = detect_anomalies(stats)
# Step 5: Report (LLM call #3)
report = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Following plan: {plan}\nReport: {interpretation}, anomalies: {anomalies}"}]
).choices[0].message.content
return reportIf detect_anomalies fails due to a network timeout, you’ve wasted two LLM calls and have to redo everything.
With Pydantic AI + Prefect
Pydantic AI has native integrations with workflow orchestrators. Here’s the same agent wrapped for durable execution:
# durable_agent_prefect.py
from pydantic_ai import Agent
from pydantic_ai.durable_exec.prefect import PrefectAgent, TaskConfig
agent = Agent(
"openai:gpt-4o-mini",
name="data_analyst", # Required for Prefect flow identification
instructions="You are a data analyst. Be concise.",
)
# Tools are automatically wrapped as Prefect tasks
@agent.tool_plain
def calculate_statistics(data: str) -> dict:
"""Calculate basic statistics on the dataset."""
return {"mean": 42.5, "std": 12.3, "count": 100}
@agent.tool_plain
def detect_anomalies(stats: str) -> list:
"""Detect anomalies - Prefect retries this automatically on failure."""
return ["No anomalies detected"]
# Wrap for durable execution
prefect_agent = PrefectAgent(
agent,
model_task_config=TaskConfig(
retries=3,
retry_delay_seconds=[1.0, 2.0, 4.0], # Exponential backoff
timeout_seconds=30.0,
),
tool_task_config=TaskConfig(retries=2, timeout_seconds=10.0),
)
async def main():
result = await prefect_agent.run(
"Analyze this dataset: [1, 2, 3, 4, 5, 100]. "
"Calculate statistics, detect anomalies, then summarize."
)
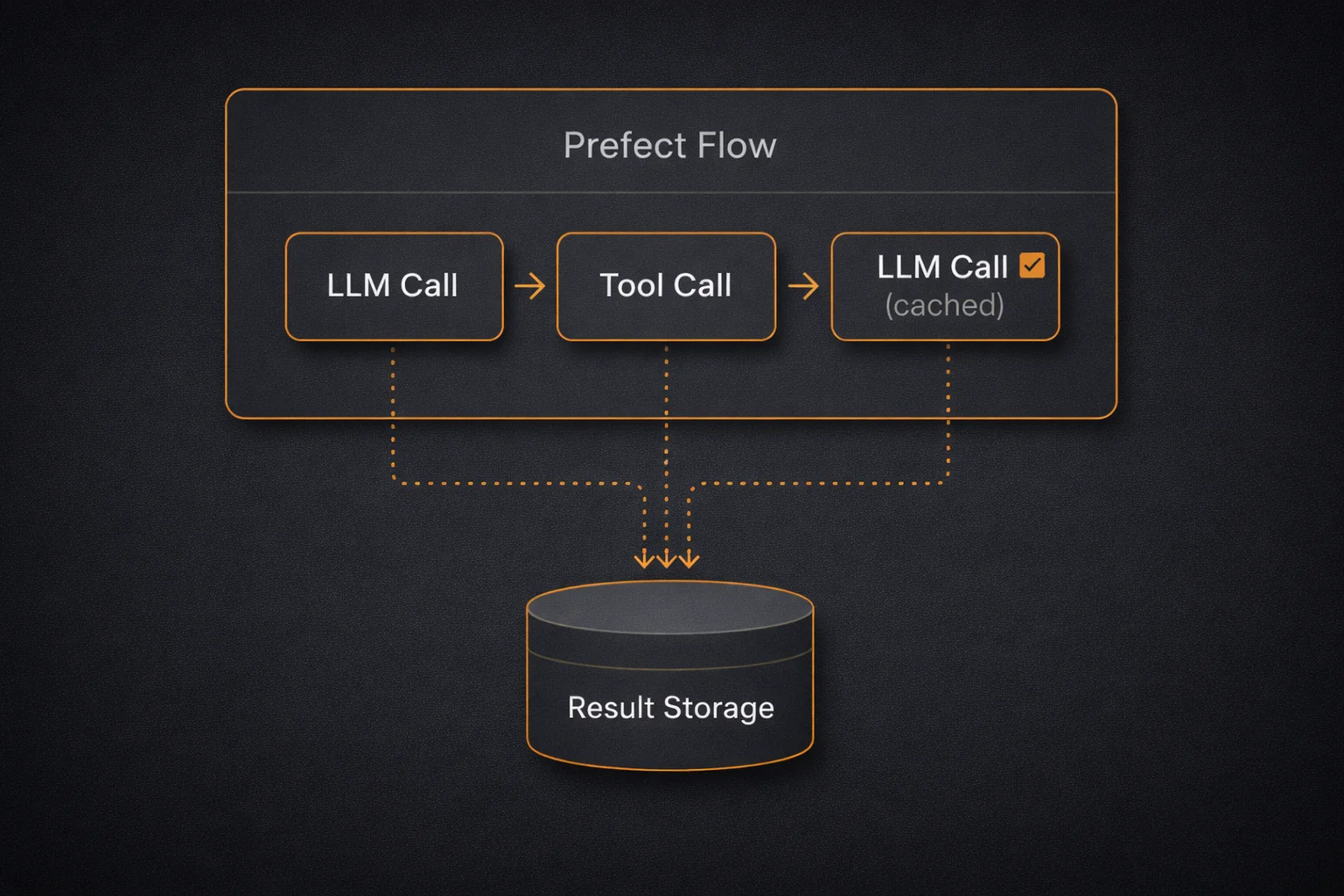
print(result.output)That’s it. PrefectAgent wraps every model request and tool call as a Prefect task. If step 4 fails, steps 1-3 results are cached. On retry, you pick up where you left off. No wasted API calls.
The architecture looks like this:
With Pydantic AI + Temporal (Process-Crash Durable)
Prefect handles task failures. Temporal goes further: it survives process crashes. If your worker dies mid-execution, Temporal replays the workflow from its persisted history:
# durable_agent_temporal.py
import uuid
from temporalio import workflow
from temporalio.client import Client
from temporalio.worker import Worker
from pydantic_ai import Agent
from pydantic_ai.durable_exec.temporal import (
AgentPlugin, PydanticAIPlugin, TemporalAgent,
)
agent = Agent(
"openai:gpt-4o-mini",
name="data_analyst",
instructions="You are a data analyst. Be concise.",
)
@agent.tool_plain
def calculate_statistics(data: str) -> dict:
return {"mean": 42.5, "std": 12.3, "count": 100}
@agent.tool_plain
def detect_anomalies(stats: str) -> list:
return ["No anomalies detected"]
# Wrap for durable execution
temporal_agent = TemporalAgent(agent)
@workflow.defn
class DataAnalysisWorkflow:
"""Deterministic workflow - Temporal replays this on failure."""
@workflow.run
async def run(self, prompt: str) -> str:
result = await temporal_agent.run(prompt)
return result.output
async def main():
client = await Client.connect("localhost:7233", plugins=[PydanticAIPlugin()])
async with Worker(
client,
task_queue="data-analysis",
workflows=[DataAnalysisWorkflow],
plugins=[AgentPlugin(temporal_agent)],
):
output = await client.execute_workflow(
DataAnalysisWorkflow.run,
args=["Analyze [1,2,3,4,5,100]. Stats, anomalies, summary."],
id=f"analysis-{uuid.uuid4()}",
task_queue="data-analysis",
)
print(output)Temporal separates deterministic workflow logic (what to do) from non-deterministic activities (LLM calls, tool executions). The workflow can be replayed identically; activities are only re-executed if they didn’t complete.
The Three Pillars
An agent system rests on three pillars:
| Component | Role | Database Equivalent |
|---|---|---|
| Agent Code | Logic & orchestration | Application code |
| LLM | Compute (reasoning) | Query engine |
| Persistent State | Memory & checkpoints | The actual database |
The third pillar, persistent state, is where most teams underinvest. They treat it like a scratchpad instead of a proper data system.
What Should You Actually Do?
If you’re building agents for production:
-
Treat memory as a database. Schema it. Back it up. Add access controls. Know what your agent “believes” and why.
-
Use workflow orchestration. Prefect, Temporal, or even just a state machine. Don’t let failures restart entire chains.
-
Design for idempotency. Every tool call should be safe to retry. Use idempotency keys for external side effects.
-
Checkpoint aggressively. Save state after each step. Disk is cheap; GPT-4 calls aren’t.
-
Log everything. An agent’s reasoning trace is like a database transaction log. You’ll need it for debugging and auditing.
The “agentic AI” future isn’t about smarter models. It’s about wrapping models in the same durable infrastructure we’ve built for traditional systems. The teams that figure this out first will build agents that actually work in production.
The code examples in this post use Pydantic AI’s native integrations with Prefect and Temporal. Both are production-ready and well-documented.
Related Posts
The Archeology of Agent Frameworks
Digging through five generations of agent frameworks, from raw API loops to federated swarms. How the developer went from outer shell to inner kernel, why each generation compressed faster than the last, and why the cycle is restarting.
Overnight Agents: Crunching Tokens
I launched an orchestrator that managed 7 Claude Code peers across repos simultaneously. They found SQL injections, fixed a 9x cost bug, built new features, and shipped 130+ commits while I slept.
Agent Drift: How Autonomous AI Agents Lose the Plot
Autonomous AI agents degrade over long-horizon tasks through accumulated context pollution, not single failures. What agent drift is, why it happens, and how to architect against it.