
AI and the Future of Programming: Architects of Intent
The Historical Accident of Syntax
Software engineering has always been about writing logic in text files. This was a practical necessity. Machines couldn’t understand what we actually wanted, so we had to spell it out in syntax they could parse.
For seventy years, since the von Neumann architecture, the core problem has been the same: computers need explicit step-by-step instructions, but humans think in terms of goals and context. The programmer’s job was to translate between these two worlds.
Whether writing Fortran in 1957 or Rust in 2024, the work is fundamentally the same: take what you want to happen, figure out how to express it in code, and debug the inevitable mismatches. Syntax errors, type mismatches, and memory leaks are all just translation failures.
The industry has spent decades trying to make this easier. Assembly gave way to C, C gave way to managed languages like Python. Each step abstracted away some complexity. But the programmer still had to write the code.
That’s starting to change.
The AI Compiler
The mental model that clarifies this shift: the AI is not an assistant. It is a compiler.
Consider what a traditional compiler does:
- Input: High-level language (C, Rust, Go)
- Process: Deterministic transformation
- Output: Low-level language (Assembly, Machine Code)
Now consider what happens when using Claude Code, Cursor, or similar tools:
- Input: Natural language intent + context
- Process: Probabilistic mapping of intent to syntax
- Output: Executable code (Python, TypeScript, Rust)
The structure is identical. The input language has changed. The AI is compiling English into Python.
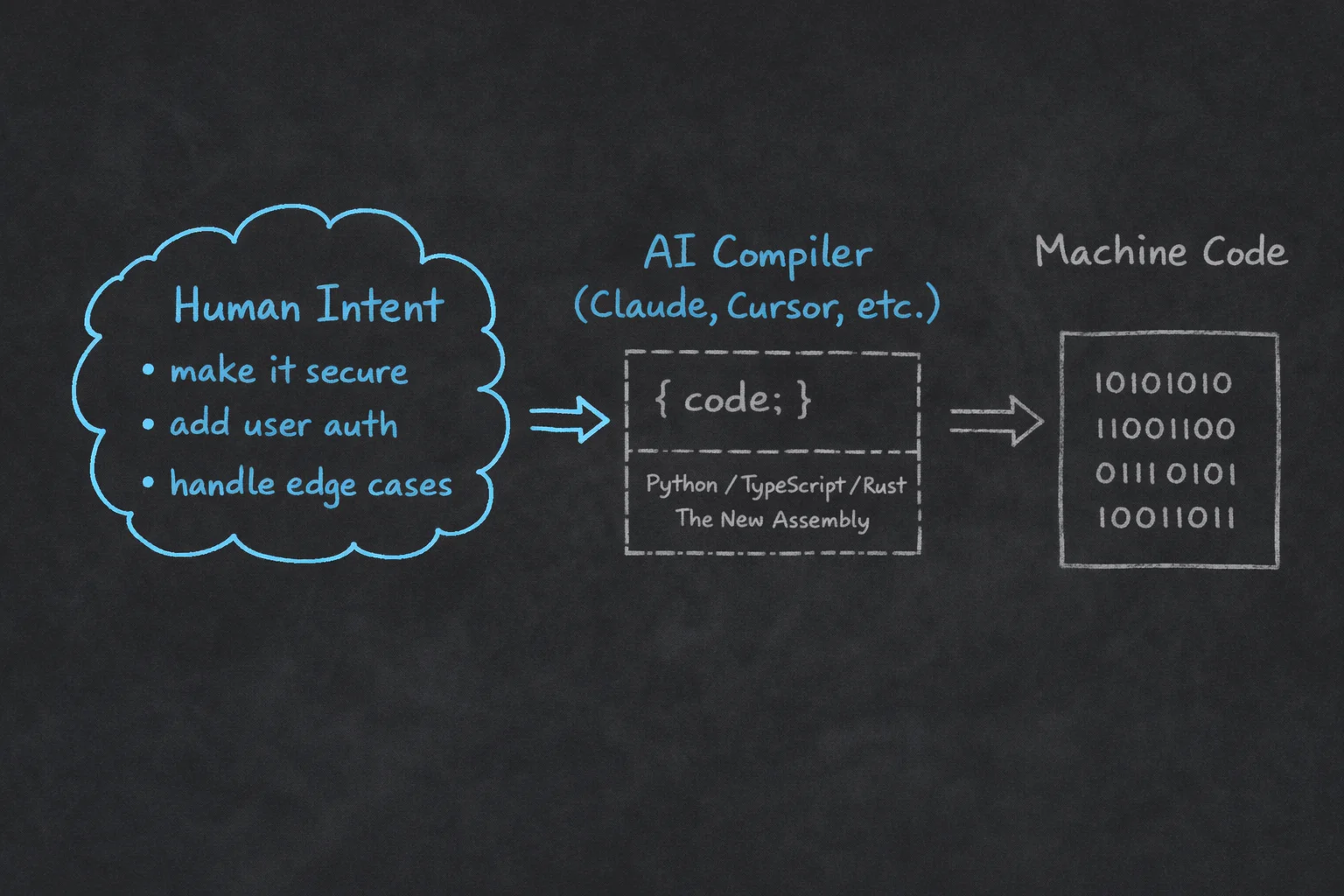
In this stack, Python is no longer the “high-level language.” It is the intermediate representation. It is the New Assembly.
This has happened before. When FORTRAN appeared in 1957, skeptics argued that compiled code would never match hand-tuned Assembly for performance-critical applications. John Backus’s team at IBM proved otherwise. Compiler optimization eventually exceeded what humans could reasonably achieve by hand. Today, Assembly is reserved for embedded systems, kernel code, and specific performance hotspots.
The pattern is repeating with AI-generated code. Current limitations (hallucinations, security vulnerabilities, inconsistent quality) are real. But they’re engineering problems, not fundamental barriers. As the AI Compiler improves, the economic case for hand-written syntax weakens.

Code as Transient Artifact
If AI can regenerate code from intent in seconds, why are we maintaining code at all?
Traditionally, code is a long-lived asset. You commit it, review it, refactor it over years. Technical Debt accumulates because the code sticks around and degrades.
But if code can be regenerated on demand, it becomes transient. Requirements change? Just update the spec and regenerate. The code isn’t the source of truth anymore; the intent specification is.
This fundamentally changes what we version control:
| Traditional Model | Intent-Based Model |
|---|---|
| Git tracks code changes | Git tracks intent changes |
| ”Who changed line 45?" | "Who changed the requirement?” |
| Refactoring is expensive | Refactoring is free (regenerate) |
| Code is source of truth | Intent specification is source of truth |
What becomes the primary asset? The Intent Repository: the collection of prompts, constraints, and context that drive generation.
- Prompts: Natural language specifications
- Constraints: Security, performance, compliance boundaries
- Context: Business logic, schemas, API contracts
We don’t check in .pyc files. If .py files can be regenerated from spec, why check those in either?
This sounds radical, but we already do it elsewhere. Nobody versions the HTML that React components render. Nobody commits compiled binaries. The source matters; the output is derived.
The Economics of Ambiguity
If code is disposable, what’s the new cost center?
Technical Debt (messy code, poor docs, tight coupling) becomes less relevant. Since you can regenerate code instantly, refactoring is basically free. Ask the AI to restructure a module and it just does it.
The new liability is Ambiguity Debt: vague, conflicting, or incomplete specifications. If your requirements have gray areas, the AI will generate inconsistent implementations. It will hallucinate details you didn’t specify. And when it does, you can’t fix it by debugging the code.
You cannot debug the code to fix Ambiguity Debt. You must debug the intent.
# High Ambiguity Debt:
"""
Build a user authentication system that's secure.
"""
# The AI must guess: OAuth? JWT? Sessions? 2FA? Rate limiting?
# Each guess compounds into potentially wrong architecture.
# Low Ambiguity Debt:
"""
Build user authentication with:
- JWT tokens (RS256, 1hr expiry, refresh tokens with 7d expiry)
- OAuth2 support for Google and GitHub
- Rate limiting: 5 failed attempts → 15min lockout
- 2FA via TOTP (optional, user-enabled)
- Password requirements: 12+ chars, complexity check via zxcvbn
- Audit log all auth events to the events table
"""
# Clear constraints. Minimal room for hallucination.The economics flip:
- Creation cost: Near zero. Scaffold a feature in seconds.
- Precision cost: High. Verifying correctness becomes the main expense.
- Asset value: Not the codebase (any AI can regenerate it from the same specs), but the Context Repository, which holds your accumulated knowledge, business rules, and data.
The Verification Gap
We’re in an awkward transitional phase.
AI generates code faster than we can verify it. Recent research quantifies this gap:
- AI adoption linked to 154% increase in pull request size
- 91% increase in code review time
- AI-generated code contains 10.83 issues per PR compared to 6.45 for human code
- 1.88x more likely to introduce improper password handling
- 2.74x more likely to introduce Cross-Site Scripting vulnerabilities
The paradox: AI-generated code is readable enough that you feel like you should review it, but there’s too much of it to review effectively.
So developers do “vibe checks”: glance at the code, see that it looks reasonable, and merge it. This is how subtle security bugs slip through.
The solution isn’t going back to manual coding. It’s building better automated verification, treating generated code as truly invisible bytecode that gets validated by machines, not humans.
Tooling the Transition
The IDEs are adapting. We’re moving from text editors to “agentic IDEs” where AI isn’t just autocomplete. It’s an agent that can plan, execute, and correct.
Cursor saves a checkpoint before every AI action. If the AI breaks something, you roll back. Their “Shadow Workspace” runs linters in the background, catching errors before you see them.
Windsurf’s Cascade tracks what you’re doing (file edits, terminal commands, cursor movements) and builds context automatically. It figures out what you’re working on without you having to explain.
Replit Agent goes furthest: Plan → Build → Test → Deploy in a loop. It breaks down requests into steps, writes code, runs it, reads errors, and fixes them. Human debugging workflow, automated.
These aren’t just faster typewriters. They’re early interfaces for Context Engineering, curating the information that feeds the AI compiler.

The Crisis of Precision
Natural language is a bad interface for precise logic.
Edsger Dijkstra made this argument in his 1978 paper “On the Foolishness of Natural Language Programming.” His point: natural language relies on shared context and social nuance to resolve ambiguity. Machines don’t have that context. What sounds clear to a human can be meaningless or contradictory to a formal system.
Leslie Lamport encountered this when specifying distributed protocols. His experience with Paxos showed that English descriptions of consensus algorithms invariably contain subtle bugs. Only formal specification (TLA+) could capture the actual invariants. The prose version always missed edge cases.
When you tell an AI to “make the system secure,” what does that mean?
- Encrypt data at rest?
- Require 2FA?
- Block external IPs?
- Rate limiting?
- Input sanitization?
- CORS policies?
- SQL injection protection?
The AI has to guess. If it guesses wrong, you get code that compiles, passes tests, and has a security hole that only shows up when someone exploits it.
Two approaches are emerging:
1. Structured Prompting: Use JSON schemas instead of chat. Typed fields constrain what the AI can do:
{
"feature": "user_authentication",
"security": {
"token_type": "JWT",
"algorithm": "RS256",
"expiry": "1h",
"refresh_expiry": "7d"
},
"rate_limiting": {
"max_attempts": 5,
"lockout_duration": "15m"
},
"audit": {
"events": ["login", "logout", "failed_attempt", "password_change"],
"destination": "events_table"
}
}Less natural, more precise. The AI fills in typed fields instead of interpreting open-ended prose.
2. Neurosymbolic Verification: A more rigorous approach combines neural networks with symbolic logic. The workflow: LLM translates natural language into formal specification (TLA+, Alloy, or Z3 constraints), a symbolic engine verifies logical consistency and safety properties, then code is generated from the verified spec. This adds overhead but provides mathematical guarantees. For mission-critical systems (aerospace, medical devices, financial infrastructure), this may be the only acceptable path.
The Human Element
This doesn’t mean engineers disappear. It means the job changes.
The shift is from procedural thinking (“How do I sort this list?”) to declarative thinking (“I need this list sorted by relevance, with recently viewed items boosted”). You stop writing implementations and start writing specifications.
The new skills:
Specification Engineering: Writing clear, unambiguous prompts. A good prompt generates correct code. A vague prompt generates debugging cycles.
Socratic Debugging: Instead of reading stack traces, you interrogate the AI. “Why this library?” “What happens if latency exceeds 500ms?”
Behavioral Verification: Test against business intent, not implementation details. Does the system do what it’s supposed to? The code is irrelevant.
This raises a pedagogical concern: how do junior developers learn?
The traditional path: write simple programs, encounter bugs, develop mental models of how code executes. If AI handles the simple programs, that feedback loop breaks. Juniors might learn to prompt effectively without understanding why the generated code works, or when it doesn’t.
Matt Welsh (former Harvard CS professor, now at Google) argues that CS curricula need to shift from “teaching syntax” to “teaching systems.” Less time on data structures in Java, more time on distributed systems, formal methods, and architectural reasoning. The skill of writing a binary search matters less than understanding when binary search is the wrong choice.
The Post-Syntax Era
After seventy years of writing code manually, we’re finally building tools that automate the process.
The time from “I want X” to “I have X” is shrinking. Ideas that took weeks to prototype now take hours. That’s a big deal.
The catch: speed requires precision. The machine builds exactly what you ask for. If you don’t know how to ask precisely, you get garbage.
The future of software engineering isn’t in the text editor. It’s in:
- The Context Controller (curating what the AI knows)
- The Formal Specification (unambiguous intent)
- The Intent Repository (versioned prompts and constraints)
Engineers won’t be judged by whiteboard coding questions. They’ll be judged by how clearly they can specify what they want.
The compromise of Code is ending. The discipline of Intent is beginning.
Related Posts
The Archeology of Agent Frameworks
Digging through five generations of agent frameworks, from raw API loops to federated swarms. How the developer went from outer shell to inner kernel, why each generation compressed faster than the last, and why the cycle is restarting.
Overnight Agents: Crunching Tokens
I launched an orchestrator that managed 7 Claude Code peers across repos simultaneously. They found SQL injections, fixed a 9x cost bug, built new features, and shipped 130+ commits while I slept.
Agent Drift: How Autonomous AI Agents Lose the Plot
Autonomous AI agents degrade over long-horizon tasks through accumulated context pollution, not single failures. What agent drift is, why it happens, and how to architect against it.