
MLOps for Startups: A Decision Framework
Machine Learning Operations (MLOps) is more than just deploying models—it’s about streamlining the entire machine learning lifecycle from end to end. For startup founders looking to leverage AI, knowing when and how to invest in MLOps can feel tricky. Too much, too soon can bog down progress; too little, too late can lead to chaos. In this post, we’ll break down a practical approach to MLOps for startups: when to start building ML infrastructure, how to do it in a lean way, and what pitfalls to avoid.
MLOps Is More Than Model Deployment
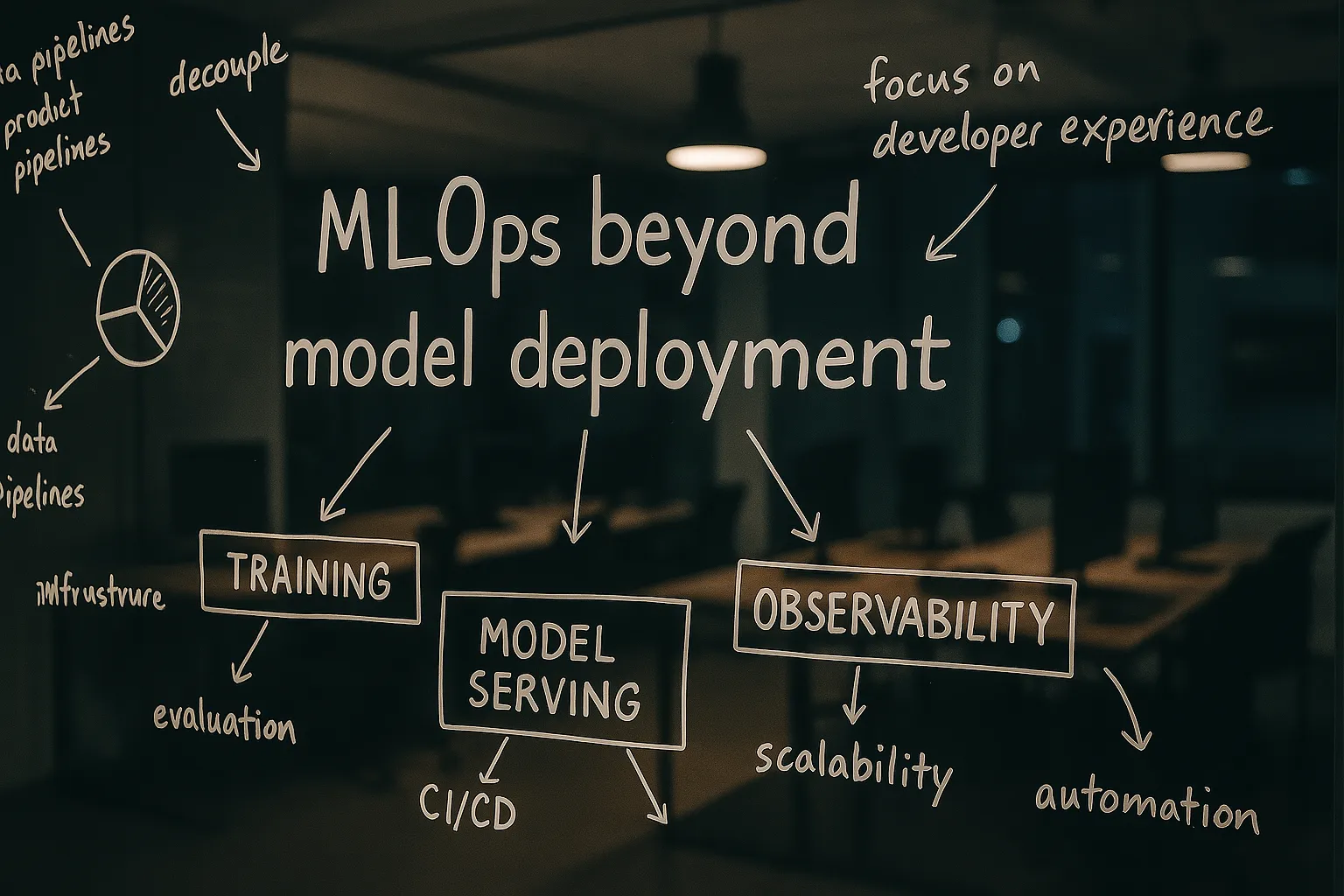
Let’s start by clarifying what MLOps actually means. MLOps isn’t just “DevOps for ML models” or pushing models to production. Instead, it’s the DevOps principles of toil prioritisation, CI/CD, Observability and Monitoring applied across the Machine learning lifecycle. It’s a broad discipline focused on optimizing the entire ML workflow:
- Data pipelines for training – how you collect, preprocess, and version the data that trains your models.
- Training infrastructure – the computing environment and tools for model development (GPUs/TPUs, distributed training, etc.).
- Model deployment and serving – getting models into production reliably, whether that’s as an API, in-app feature, or batch process.
- Observability and monitoring – tracking model performance, data drift, latency, and failures in production.
- Automation and workflows – CI/CD for ML, reproducible experiments, and orchestrating jobs from training to deployment.
In short, MLOps is about making the entire ML lifecycle faster, more efficient, and more reliable. A solid MLOps practice covers everything from raw data to delivered predictions. Keep this holistic definition in mind as you plan your investments—if you only focus on deploying models, you’re missing 90% of the picture.
Early Stage: Share the Load and Stay Flexible

In the very early days of a startup, you likely don’t have the luxury of dedicated MLOps engineers. And that’s okay! Early on, machine learning engineers (MLEs) and software engineers should share the workload of model building, data engineering, and deployment. It’s common at this stage for the same person to train the model and set up a simple API or pipeline to serve it. This all-hands-on-deck approach keeps process overhead low and speed high (there’s little to no “red tape”). You’re closer to the metal, iterating directly on models and data without a lot of ceremony.
The key in this phase is staying flexible. Avoid locking yourself into complex, rigid ML pipelines or heavy tooling too soon. As one MLOps veteran observed, “thinking about deployment and efficiency too early in the lifecycle of a project is a terrible idea” . At the start, your focus should be on rapidly exploring the problem space—trying out different models and collecting feedback—rather than perfecting your infrastructure. A minimally structured, ad-hoc environment often leads to faster discovery and iteration in these early days.
Don’t Invest in MLOps Too Early. One of the biggest mistakes a young ML-driven startup can make is over-investing in an elaborate MLOps stack at the discovery stage. If you’re pre-Series A and still figuring out your product-market fit or your core ML model, spending months building a “full” pipeline or a bespoke ML platform can be counterproductive. Why? Because heavy processes can constrain your ability to build and experiment. You might end up forcing a certain workflow or data schema before you truly understand the problem. Inflexible infrastructure is the enemy of innovation in the nascent stage.
Instead, prioritize developer experience with lightweight tools. Make it easy for your ML engineers to train and test models, preferably with just a few commands or clicks. For example, use notebooks or simple scripts for experimentation, and use standard software engineering best practices (like Git for version control, and maybe Docker for consistent environments) to keep things manageable. You want just enough structure to avoid total chaos – think simple data versioning, basic experiment tracking (even if it’s a spreadsheet or a few database tables), and one-step model deployment scripts. Every addition should solve a clear pain point the team is feeling. Save the heavy-duty MLOps pipeline for later, when you have more people and a clearer direction.
When to Bring in Dedicated MLOps: After Product Validation

How do you know when it’s time to get serious about MLOps? A good rule of thumb: wait until you have a small herd of ML models or a larger ML team (say 5–10 MLEs) before hiring dedicated MLOps engineers or building out a complex infrastructure. Often, this inflection point comes post-Series A, when the company has users, funding, and a mandate to scale. At that stage, the “move fast and break things” approach to ML can start breaking the wrong things (like customer trust, or the on-call engineer’s sleep schedule).
Bringing in a dedicated MLOps engineer (or team) after Series A means you have enough models and engineers to keep them busy. Their job is to formalize and streamline what the team has been doing manually. They’ll take those glue scripts and one-off pipelines and turn them into more robust, automated workflows. Crucially, they can focus on infrastructure improvements that individual MLEs didn’t have time for—like better monitoring, automated retraining, and scalable deployment setups—without slowing down model innovation.
At this point, investing in MLOps will pay off in developer productivity and reliability. Your MLEs will thank you as training and deployment become more “push-button” and less bespoke. Just remember: even with specialists onboard, keep the culture collaborative. MLOps folks should work hand-in-hand with MLEs, not gate them. The last thing you want is to introduce bureaucracy right as you’re trying to accelerate.
Be Surgical with Tooling and Infrastructure

When you do start adding MLOps tools and infrastructure, take a surgical approach. Rather than adopting a giant platform that claims to do everything, add tools incrementally that solve specific pain points – ideally, tools that can tackle multiple issues at once. Think of it like upgrading parts on a car one by one, not replacing the whole engine while you’re still tuning it.
For example, suppose your team is struggling with deploying models for testing because it’s a manual, error-prone process. Introducing a simple deployment automation tool or using a serverless platform for model serving can kill two birds with one stone: it makes deployment easier and also enables new workflows. One cool developer flow it enables is branch-based model deployments using serverless compute. Imagine each Git branch or pull request spinning up its own ephemeral model API endpoint for QA – this lets you test models in isolation, compare different versions live, and tear them down easily when you’re done. A small addition like that empowers your team to experiment freely without a ton of overhead.
Another surgical strike might be using a single tool to cover experiment tracking and model registry. Early on, you might not need separate systems for these. A tool like MLflow, ClearML or Weights & Biases could log experiments, and the saved artifacts (or a simple database) can double as a lightweight model registry. The goal is to choose additions that deliver outsized benefits. Each new component in your stack should either replace a tedious manual step or unlock a capability you didn’t have (with minimal maintenance cost). Avoid the temptation to install a seven-part “MLOps platform” all at once – you’ll end up spending more time integrating and babysitting tools than training models.
Make Data a First-Class Citizen

No matter how fancy your models, they’re only as good as the data feeding them. MLOps must put serious emphasis on data pipelines and data infrastructure. This is one area where startups often learn hard lessons, so here are some key principles:
- Decouple execution, orchestration, and registry: In data pipelines, separate the concerns of execution (the heavy lifting computation), orchestration (the scheduling and workflow logic), and registry (tracking data/model metadata). For instance, you might use a scalable execution framework like Apache Beam for large-scale data processing, orchestrate pipeline runs with a modern workflow tool like Dagster or Prefect, and keep a simple database or file store as your “registry” of datasets and models. Decoupling these pieces gives you flexibility — you can upgrade or swap out one component without derailing everything else.
- Remember: training data pipelines ≠ product data pipelines: The pipelines that prepare your training data are not the same as your real-time product data flows. Don’t try to force one system to do both. Your product pipeline (say, an ETL feeding data into your app or a streaming service updating features) has different requirements and cadence than a training pipeline that might crunch through a year of historical data to create a dataset. Design dedicated processes for ML data prep, and treat them as first-class projects. You might need to backfill data, join across sources, or generate labels in ways that the production data pipeline doesn’t. A tool like Beam (or Spark, etc.) can help crunch big training datasets efficiently, separate from your user-facing systems.
- Use new-gen orchestrators over Airflow: When it comes to scheduling and coordinating ML workflows, newer tools like Dagster and Prefect are often a better fit than the old guard (Airflow). Why? They’re built with data science in mind – offering easier Python integration, type-safe data handling, and more modern UIs. Airflow was a great general ETL orchestrator, but it can be heavy and clunky for complex ML pipelines. In contrast, Dagster and Prefect let you write workflows as code with minimal boilerplate, handle data passing between steps gracefully, and have a more pleasant developer experience (which your team will appreciate). If you’re starting fresh, it’s worth evaluating these newer options to avoid technical debt from day one.
- Don’t over-engineer your data/model registry early: It’s easy to get carried away designing a perfect metadata store or model registry. But in the early stages, you often don’t need a fancy dedicated system for this. A simple table in SQL or even a Google Sheet can track which dataset version and hyperparameters went into “Model v1.2” and where that model file lives. The important part is capturing the info, not what format it’s in. As you grow, you can graduate to a proper model registry or feature store. But many companies waste time building complex registries too soon. Remember that simplicity scales surprisingly well in the beginning.
MLOps and ML Engineering: Blurring the Lines

As you invest more in MLOps, you’ll notice the line between an “ML engineer” and an “MLOps engineer” can get pretty blurry. And that’s a good thing. In practice, a strong MLOps engineer will dive into research or model code, and an ML engineer will contribute to tooling when needed. MLOps isn’t a siloed DevOps team pushing buttons from afar; they’re in the codebase alongside data scientists. In fact, they often make small tweaks to model code that have huge downstream benefits.
For example, an MLOps engineer might suggest using the “right GPT stack” for a large language model project – say, swapping in a library that better optimizes transformer execution. By introducing BitsAndBytes (an 8-bit quantization library) into the training code, they could drastically reduce the model’s memory footprint with minimal accuracy loss. That change might enable the model to train on a single GPU instead of four, or to serve on cheaper hardware. Likewise, they might integrate an efficient serving engine like vLLM for deployment, which can boost throughput for GPT-style models. These kinds of improvements require touching the model code and understanding its dynamics.
The takeaway: MLOps engineers must be comfortable working in the “research” code. Whether it’s optimizing a training loop, refactoring a data preprocessing script for production, or implementing a custom metric for evaluation, the best MLOps people move fluidly between infrastructure and ML logic. In modern teams, roles overlap – some folks joke that “everyone is a bit of an MLOps engineer now.” What matters is not job titles but skill sets: a blend of software engineering, cloud/devops, and understanding of ML modeling.
LLMOps: Hype and Reality

Everywhere you turn, there’s talk of “LLMOps” – tooling and practices specifically for Large Language Models. Yes, working with LLMs (like GPT-3/GPT-4 and similar) introduces new challenges (huge models, prompt management, etc.), but don’t let the hype confuse you. The core principles remain MLOps 101: version your models and data, automate what you can, and monitor everything. The biggest new emphasis in LLMOps is on observability and tracing of model behavior. Think of it as adding extra logging around your model’s decisions, much like you’d use Grafana or other observability tools for traditional services.
For example, when your application calls an LLM to generate some text or answer a query, you want to capture the entire sequence of what happened – the prompt, the internal reasoning steps (if you use frameworks like LangChain), and the output. This tracing is incredibly valuable. It lets you debug issues (why did the model respond a certain way?), and it creates a data trail you can mine later. In fact, tracing is the foundation for dataset distillation: taking transcripts of your model’s interactions with users and filtering or aggregating them to create new training data. By analyzing traces, you might discover common failure modes or missed edge cases, which you can then address by fine-tuning the model or adjusting prompts.
In short, the real value behind the LLMOps buzz is better visibility into these complex model workflows. One observability expert put it simply: tracking the sequence of operations in an LLM application is critical for debugging and improvement. So if you’re diving into LLMs, invest in good logging/monitoring of model calls and perhaps tools that visualize this (some companies are building “LLM trace” viewers). It’s less about inventing completely new ops and more about extending tried-and-true practices to a new kind of ML workload.
Don’t Bet on One Platform – Invest in Glue

The landscape of ML tools is highly fragmented. There’s no single platform that does everything your team needs (despite what some vendor marketing might claim). You’ll likely end up using a mix of cloud services, open-source tools, and custom scripts to cover all stages of the ML lifecycle. This is normal – in fact, it can be a strength if you embrace it. Rather than hoping one “MLOps platform” will magically solve all problems, invest in the glue that holds your ecosystem together.
By glue, we mean the integration layer: conventions, APIs, and connectors that allow data and context to flow between tools. For example, you might write a small script or use a webhook so that when a model is registered (in whatever storage or registry you use), it automatically triggers the deployment pipeline. Or ensure that your feature engineering code is packaged in a way that it can be used both in offline training and in the live inference server – so you don’t end up rewriting logic twice. A bit of forethought on how pieces connect will save you massive headaches.
Crucially, focusing on glue guards against vendor lock-in. If you’ve built clean interfaces between, say, your training code and your serving system, you can swap out the serving part down the road without having to rewrite the training pipeline. This is important because the ML tooling world changes fast. Today’s state-of-the-art tool might be obsolete in a year. Flexibility is your friend. As one industry expert noted, the idea of a one-size-fits-all “end-to-end” ML platform is essentially fiction – even big cloud platforms end up being just one piece of your puzzle. So, design your MLOps with modularity in mind.
Keep Your Eyes on the Prize: Product Impact

Finally, remember why you’re investing in MLOps in the first place: to drive business and product value from machine learning. It’s easy to get caught up in tools and tech, but successful MLOps teams also define clear evaluation frameworks and metrics that align with product goals. This means working with product managers and data scientists to decide what success looks like for your models in the real world.
For example, if you have a recommendation model, the MLOps team might help set up an offline evaluation that correlates strongly with downstream metrics like click-through rate or revenue per user. They might build pipelines to regularly evaluate new models on not just accuracy or AUC in the lab, but also scenario-based metrics (did the recommendations diversify content? did they retain users?). Moreover, in production, MLOps should ensure that monitoring includes business KPIs. It’s not just “is the service up and the model response time fast,” but also “are we seeing improvements in user engagement since the last model deploy?”
By keeping metrics tied to product value, MLOps engineers become partners in the product development process, not just toolsmiths. They provide the data to answer: Did our latest model update actually make a difference for users? This closes the loop from idea to implementation to impact. And it prevents the common pitfall of ML teams chasing metric improvements that don’t translate to real-world gains.
Conclusion: Evolve Your MLOps Step by Step

For a startup founder or tech lead, the guiding principle should be to evolve your MLOps incrementally alongside your team’s needs. Start lean and flexible when you’re in exploration mode. As you gain traction, layer in more structure and automation to turbocharge your ML efforts (without suffocating them). Think of MLOps investment not as a one-time decision, but as a continuum:
- In the beginning, do the simplest thing that works. Manual is fine if it’s manageable.
- As you get a few wins and your ML efforts expand, shore up the cracks with targeted tools (better data pipeline, one-click deploys, monitoring dashboards).
- Once you have multiple models/products relying on ML, bring in specialists and heavier infrastructure to ensure reliability and scalability.
Through it all, keep the focus on enabling fast iteration, maintaining flexibility, and delivering real value. MLOps is a means to an end – done right, it amplifies your team’s ability to build great ML-driven products. Done wrong (too early, too rigid, or too siloed), it can be a drag. With the practical, staged approach outlined above, you can avoid the pitfalls and get the timing just right.
Good luck, and happy scaling!
Related Posts
ML Infrastructure Strategy: Build for Momentum
Early architectural decisions create a flywheel effect that accelerates your path to production. Discover the Nimble Flywheel framework for scaling ML.
A Better ML Training Workflow: Stop Training and Praying
Fix your ML training workflow with the Pre-Flight, In-Flight, Post-Flight framework—catch bugs early, monitor runs, and evaluate beyond vanity metrics.
Agentic MLOps: AI Agents Automating Your ML Stack
Explore how agentic MLOps uses AI agents and MCP to autonomously handle data drift, model deployment, and ML pipeline orchestration across your entire stack.