
A Better ML Training Workflow: Stop Training and Praying
We need to talk about the elephant in the room: most ML development is embarrassingly wasteful.
I’ve watched teams burn through millions of dollars training frontier models only to discover fundamental bugs after the run completes. I’ve seen engineers religiously check their loss curves like stock tickers, praying their 3-week training job doesn’t crash overnight. And I’ve personally experienced the gut-punch of realizing that a “successful” model with 95% accuracy completely fails on the data slices that actually matter for the business.
This isn’t just about wasted money—though poor data quality alone costs firms an average of $12.9 million annually. It’s about a fundamentally broken development paradigm that’s holding back innovation.
The “Train and Pray” Problem
Here’s how most ML development actually works:
- Spend weeks preparing your dataset
- Write your model code
- Launch a massive training job
- Cross your fingers and wait
- Discover your bug/data issue/fundamental flaw after burning through your compute budget
Sound familiar? This “train and pray” approach treats ML training like a black box gamble instead of engineering. And the costs are staggering.
The Hardware Reality Check
Let’s start with the inconvenient truth about hardware failures. When Meta trained their OPT-175B model on 992 A100 GPUs, they had 35 manual restarts over two months. The Llama 3.1 405B training? 417 hardware failures in 54 days.
Here’s the math that’ll keep you up at night: a 512-instance cluster has an expected hardware failure every 5 hours. And because most teams checkpoint every 3+ hours to avoid the 30-40 minute save overhead, each failure can waste hours of the most expensive computation on earth.
The Data Pipeline Disaster
But hardware is just the beginning. Google’s analysis of millions of training jobs revealed that jobs spend 30% of their time just waiting for data. Some models spend up to 70% of their time on I/O, with your expensive GPUs sitting idle while CPUs struggle to decode and preprocess the next batch.
This creates a vicious cycle: when your data pipeline is slow, debugging becomes prohibitively expensive. Teams ship with “good enough” data because the cost of another iteration to fix subtle quality issues feels too high. Then they burn weeks of compute training on fundamentally flawed datasets.
The Silent Killers: Logic Errors
The most insidious problems don’t crash your training—they silently corrupt it. Data leakage. Incorrect preprocessing. Subtle bugs like forgetting to apply the same augmentation to both images and segmentation masks, forcing your model to learn an impossible task.
These issues often only surface when you discover your “successful” model performs terribly on critical subgroups—like Amazon’s hiring algorithm that discriminated against women because it was trained on historical male-dominated data.
Why Traditional Evaluation Is Broken
Even when training completes successfully, our evaluation methods give us false confidence. The standard practice—evaluating on a random test set with a single aggregate metric—is like judging a car’s safety by its average crash test score across all scenarios.
Random sampling fails to capture critical edge cases. Your model might achieve 99% accuracy overall while completely failing on vulnerable populations or rare but critical scenarios. You declare victory, invest more compute in hyperparameter tuning, maybe even deploy to production—all while sitting on a ticking time bomb.
A Better Way: Pre-Flight, In-Flight, Post-Flight
The solution isn’t better hardware or faster GPUs. It’s treating ML development like the engineering discipline it should be. I propose a three-phase approach that shifts validation left and makes every compute cycle count:
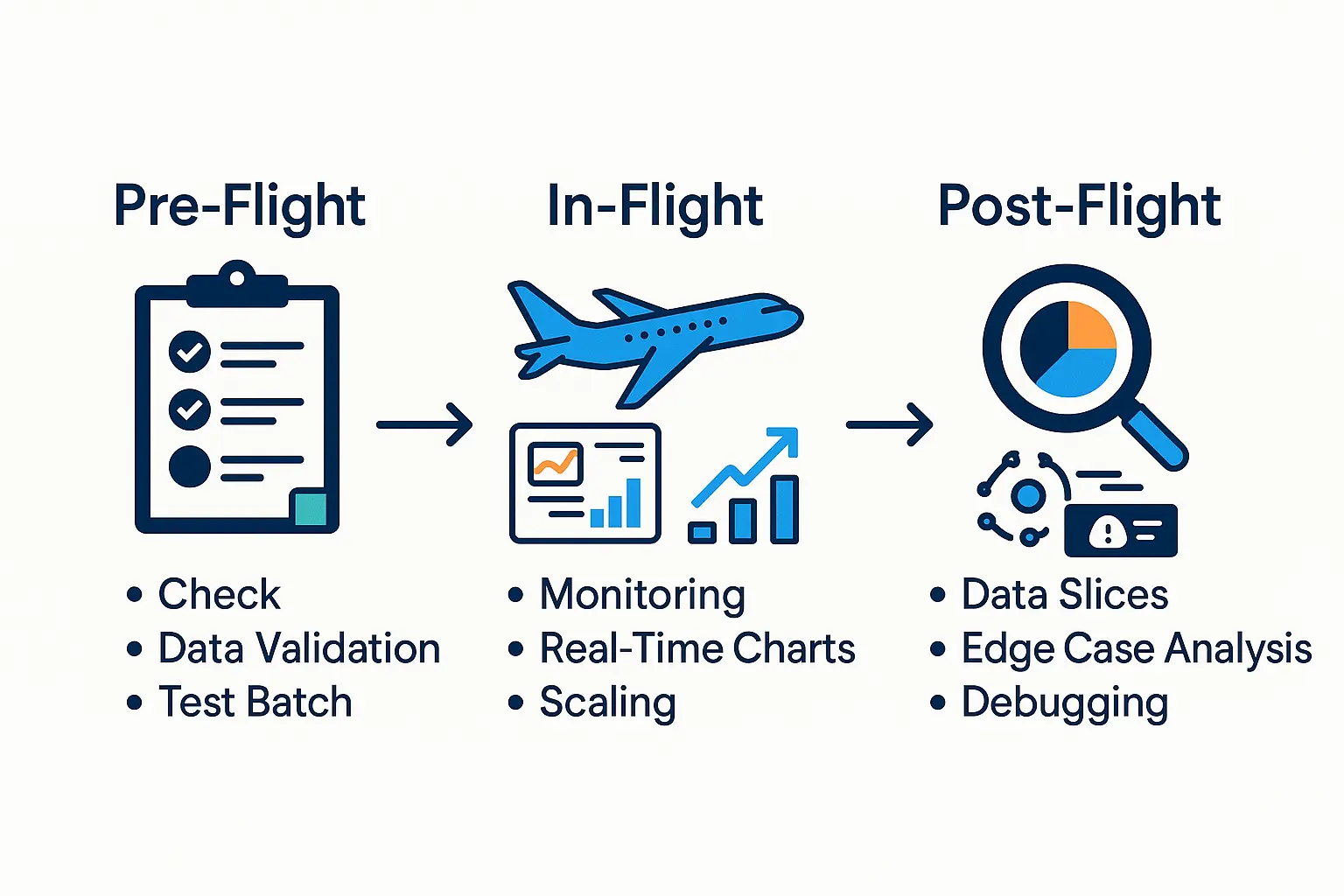
Phase 1: Pre-Flight Protocol (Before You Waste Money)
Stop launching training jobs blindly. Before you spin up that expensive cluster, run these fast, cheap checks:
- Data validation pipeline: Automated schema checks, integrity validation, and distributional analysis to catch data drift and quality issues upfront
- Memory estimation: Use the 40GB per billion parameters rule for transformers to avoid OOM crashes
- Single-batch end-to-end test: Run your entire pipeline on one batch—this catches 80% of bugs in minutes, not days
- Intentional overfitting test: Can your model overfit on 10 batches? If not, you have a fundamental problem
Phase 2: In-Flight Monitoring (Turn Training Into Debugging)
Make your training process transparent. Instead of staring at loss curves and hoping:
- Staged scaling: Start with 1% of your data, then 10%, scaling up only when each stage shows promise
- Progressive validation: Evaluate on the next unseen batch after each training step, creating a real-time generalization curve
- Real-time anomaly detection: Hook into your training loop to catch NaN values and gradient explosions the moment they happen
- Smart checkpointing: Save frequently to local storage, not remote—reduce recovery time from hours to minutes
Phase 3: Post-Flight Analysis (Beyond Vanity Metrics)
Interrogate your model like your business depends on it. Because it does:
- Curated test slices: Build targeted test sets for critical subpopulations, not just random samples
- Edge case discovery: Systematically find your model’s blind spots before your users do
- Model debugging: Run sensitivity analysis and residual analysis to understand when and why your model fails
Time to Stop the Madness
The current state of ML development is like building rockets by lighting the fuse and hoping for the best. We’ve gotten comfortable with waste because compute felt infinite and model performance kept improving despite our inefficiencies.
But as models get larger and more expensive, we can’t afford this anymore. Every failed training run is a lost opportunity to test a new idea. Every hour debugging preventable errors is an hour not spent on innovation.
The three-phase framework isn’t just about saving money—it’s about accelerating the pace of ML innovation by making our development process more scientific, predictable, and efficient.
The question isn’t whether you can afford to adopt these practices. It’s whether you can afford not to.
Related Posts
Machine Learning Training Infrastructure Guide
Scale ML models faster with the right training infrastructure. Covers distributed training, GPU clouds, spot instances, and cloud-agnostic setups.
ML Infrastructure Strategy: Build for Momentum
Early architectural decisions create a flywheel effect that accelerates your path to production. Discover the Nimble Flywheel framework for scaling ML.
Machine Learning Project Template with Modern Stack
A modality-aware machine learning project template that gets you from idea to training in minutes using uv, Polars, and LitServe for modern ML workflows.