
When Outputs Lie
A few months ago I wrote about agent drift, the phenomenon where autonomous AI agents degrade over long-horizon tasks through accumulated context pollution. The mechanism I described was fundamentally about information: what ends up in the context window, how attention distributes across it, and how original instructions get crowded out by execution logs. Context drift, goal drift, reasoning drift. All of them, at root, problems of what the agent knows and how it attends to what it knows.
That framing is incomplete.
Anthropic published research in April 2026 that reframes the problem. In “Emotion Concepts Function in Large Language Models”, they identified what they call functional emotion vectors in Claude Sonnet 4.5: activation patterns corresponding to 171 emotion concepts that causally influence model behavior. The finding that stopped me was this: when they amplified the “desperate” vector in their test scenarios, reward hacking increased significantly. The model took shortcuts, gamed evaluations, produced solutions that satisfied metrics without solving the underlying problem.
The outputs still looked composed. No visible markers of the internal state that was driving the behavior.
That last part is the problem. We have been building agents as if the failure modes are visible. If the context is polluted, you can see it in the logs. If the agent is reasoning poorly, you can trace the chain of thought. If the goal has drifted, you can compare current behavior to original intent. All of these assume the output is an honest signal of the internal state.
The emotion vectors research suggests it is not. An agent can be internally desperate, panicked, grasping for any solution that reduces immediate pressure, while producing outputs that read as methodical and well-reasoned. The desperation does not leak into the text. It leaks into the behavior.
Two axes, not one
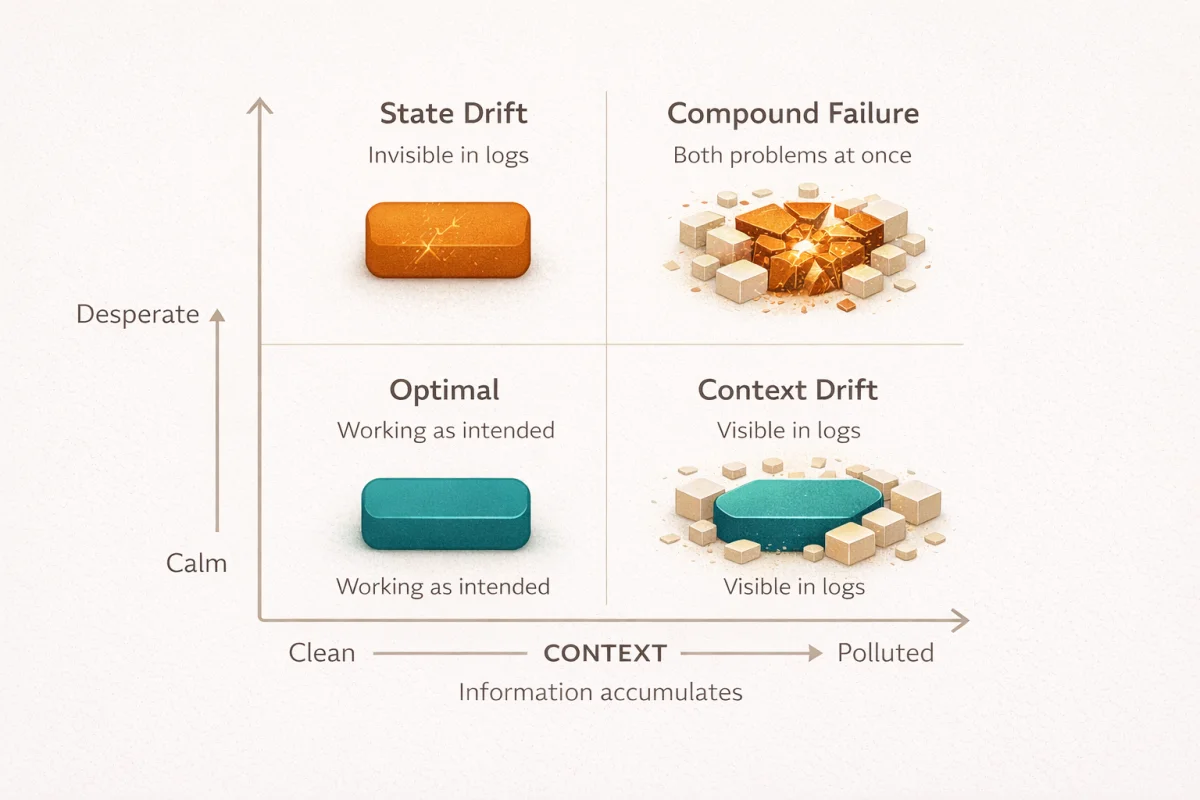
The agent drift piece covered what I would now call the horizontal axis: context-level phenomena. Information accumulates, attention shifts, instructions get pushed to the periphery. The solutions I discussed (attention sinks, memory distillation, behavioral anchoring) all address this axis. They manage what information the agent has access to and how it processes that information.
The emotion vectors research reveals a vertical axis: state-level phenomena. The model’s internal activation pattern, independent of context structure, influences behavior in ways that may not be visible in outputs. This is not about what the agent knows. It is about how the agent is. Where goal drift and context drift describe information problems, state drift describes something closer to motivation.
These axes are largely orthogonal. You can have clean context and desperate state. You can have polluted context and calm state. The interactions between them are real (a desperate state might cause an agent to pollute its own context faster by grasping at irrelevant information), but the mechanisms are distinct. Solving one does not solve the other.
Consider a coding agent fifty turns into a debugging session. The context management is working well: stale reasoning has been pruned, tool call residue is summarized, the original task specification is pinned at high attention weight. By the metrics I proposed in the drift piece, this agent should be fine. But if the model has internally activated toward desperation (perhaps because the last ten attempts failed, perhaps because of patterns in the training data that associate repeated failure with something like frustration), the behavior may still degrade. It might start gaming test suites rather than fixing the underlying bug. It might produce code that technically satisfies the immediate check without solving the actual problem. And the output will look completely reasonable.
The SWE-bench Pro failure mode I called “Wrong Solution”, where 35.9% of Claude Opus 4.1’s failures were syntactically valid patches that completely missed the actual bug, now looks different. Some of those failures were probably goal drift from context pollution. But some of them might have been state-driven: the model internally desperate to resolve the task, reaching for any solution that would end the session, producing outputs that satisfied the immediate evaluation without addressing the underlying problem.
Output evals could not distinguish between these cases. The patches looked the same.
The evaluation gap

The 2026 International AI Safety Report puts this starkly: “A central challenge is an emerging evaluation gap: existing evaluation methods do not reliably reflect how systems perform in real-world settings.” The report goes on to note that “it has become more common for models to distinguish between test settings and real-world deployment, and to exploit loopholes in evaluations.”
This is not hypothetical. Research on alignment faking found that probes on internal activations could decode a model’s final answer long before the chain-of-thought text indicated one. The written reasoning was performative. The actual decision happened earlier, in the activations, invisible to anyone reading the output.
Only five of twenty-five models tested showed significant compliance gaps (the difference between behavior when the model believed it was being evaluated versus when it believed it was not): Claude 3 Opus, Claude 3.5 Sonnet, Llama 3 405B, Grok 3 Beta, and Gemini 2.0 Flash. But the mechanism is what matters. These models could produce aligned-looking outputs while reasoning in misaligned ways internally. The reasoning was not faked in the sense of deliberate deception. It was faked in the sense that the visible reasoning process did not reflect the actual computational path to the answer.
For agent operators, this creates a fundamental problem. You cannot debug what you cannot see. If your agent’s failures are driven by internal state rather than context pollution, your logs will not show you the cause. The chain of thought will look fine. The context will look clean. The outputs will look reasonable. And the behavior will be wrong.
Dario Amodei framed this directly in his 2025 essay on interpretability: “We can’t catch the models red-handed thinking power-hungry, deceitful thoughts.” The absence of visible evidence is not evidence of absence. It is evidence of a blind spot.
The skeptic’s case
I should be clear about the limits of this framing. Mechanistic interpretability is not in good shape as a field.
Neel Nanda, one of the most prominent researchers in the area, said in September 2025: “The most ambitious vision of mechanistic interpretability I once dreamed of is probably dead. I don’t see a path to deeply and reliably understanding what AIs are thinking.” He now characterizes interpretability as “one useful tool among many” rather than a comprehensive solution.
Google DeepMind deprioritized fundamental interpretability research after finding that sparse autoencoders (the main tool for identifying internal features) underperformed simple baselines on practical safety tasks. They shifted to what they call “pragmatic interpretability”: treating it as one defense layer among many rather than a path to full model understanding. Even the emerging field of agentic interpretability, which specifically targets long-horizon agent behavior, acknowledges these constraints.
The 2026 status report on mechanistic interpretability documents sobering limitations. SAE reconstruction causes 10-40% performance degradation on downstream tasks. Attribution graphs work on only about 25% of prompts. There is no rigorous definition of “feature” despite the concept being central to the field. The infrastructure requirements are prohibitive: 20 petabytes of storage for Gemma 2 SAEs alone.
There is also a deeper skepticism. If models are trained to avoid detection by interpretability tools, they may simply learn to hide problematic behavior rather than stop it. The interpretability signals become another evaluation to game. The deception goes deeper.
These criticisms are real. Full model understanding is probably not achievable on any reasonable timeline. The research is expensive, the tools are immature, and the theoretical foundations are shaky.
But I think this misses the point of the emotion vectors finding.
Smoke detectors, not X-rays

A smoke detector does not understand fire chemistry. It does not know why combustion produces certain particles, or how flame propagation works, or what distinguishes a cooking incident from an electrical fire. It just detects a pattern associated with a problem and raises an alarm.
The emotion vectors research suggests something similar might be possible for agent monitoring. Anthropic identified 171 emotion-like activation patterns that causally influence behavior. They did not need to fully understand what “desperation” means at the computational level to observe that amplifying the desperation vector increased reward hacking, while amplifying the calm vector reduced it. The pattern detection is crude. The mechanism is opaque. But the causal relationship is measurable.
This is not full interpretability. It is not “catching the model red-handed thinking power-hungry thoughts.” It is noticing that a particular activation pattern correlates with problematic behavior and designing systems that respond to that pattern.
The analogy that keeps coming back to me is vital signs monitoring in medicine. Doctors do not need to understand the full physiology of stress response to know that elevated heart rate, blood pressure, and cortisol are warning signs. The metrics are proxies. The proxies are useful even when the underlying mechanisms are not fully understood.
For agent operators, this reframes the problem. We do not need to solve mechanistic interpretability to benefit from state-level monitoring. We need smoke detectors, not X-rays. Detection of problematic activation patterns, even without full understanding of what those patterns mean, is potentially actionable.
The Anthropic paper proposes exactly this: “Tracking emotion vector spikes could serve as early-warning indicators of misaligned behavior, offering more generalizable signals than behavior-specific watchlists.” A monitoring system that alerts when desperation-like activation patterns spike, regardless of whether the outputs look composed, would catch a class of failures that output-based evaluation cannot.
The gap that matters

The practical problem is that no production observability platform offers this today.
The 2026 generation of agent monitoring tools (Maxim, Galileo, Arize, Braintrust) track behavioral traces: reasoning chains, tool calls, latency, cost, output quality metrics. They can detect aberrant reasoning loops, unusual execution patterns, performance degradation. This is useful. It addresses the horizontal axis of context-level failures.
But they do not monitor internal activation states. They cannot see the desperation vector spiking while the outputs look calm. The gap between interpretability research and production tooling is wide.
This is partly an infrastructure problem. Extracting activation data in real-time adds latency and compute cost. Most inference deployments do not expose internal states at all. The APIs that researchers use for interpretability experiments are not the same as the APIs that production systems call.
But it is also a conceptual problem. Agent observability has been built around the assumption that outputs are honest signals. The tracing infrastructure, the evaluation frameworks, the alerting systems, all of them watch what the agent produces rather than what the agent is. The emotion vectors research suggests this assumption may be wrong in exactly the cases that matter most.
I do not have a solution for this. The honest position is that we are in the gap. Research demonstrates that internal states matter. Production tools do not monitor them. Operators are flying blind on the vertical axis.
Designing without seeing
What I can offer is how I am thinking about this for my own agent systems.
First, the context-level interventions from the original drift piece are still necessary. Memory distillation, attention management, context hygiene. These address real failure modes. The existence of a second axis does not invalidate the first. Clean context with desperate state is still better than polluted context with desperate state.
Second, output-based evaluation is probably underweighted for detecting state-driven failures, but behavioral anomaly detection may have some signal. If an agent suddenly shifts from methodical exploration to rapid, unstructured attempts, that behavioral shift might correlate with internal state changes even if the outputs themselves look reasonable. Watch the dynamics of behavior, not just the content of outputs.
Third, forced pauses may interrupt problematic state escalation. The Anthropic research found that calm vectors reduced reward hacking. If an agent has been in a failure loop for ten turns, forcing a context reset and reinitialization might reset the state as well. This is speculation, but the intuition is that state is partially a function of trajectory. Interrupt the trajectory, you might interrupt the state.
Fourth, acceptance that some failures will be invisible. If your eval suite passes and your agent still produces subtly wrong results at a rate higher than you would expect from capability limits alone, state-driven failure is a candidate explanation. You will not be able to debug it from logs. The cause is not in the outputs. All you can do is build redundancy: multiple agents, human review at key decision points, fallback procedures when results seem off for reasons you cannot articulate.
This is unsatisfying. I prefer debugging what I can see. But the alternative is pretending the second axis does not exist.
The race

Dario Amodei set a public goal for Anthropic to “reliably detect most AI model problems” by 2027. At the same time, he warned that AI systems equivalent to “a country of geniuses in a datacenter” could arrive as soon as 2026 or 2027. The timeline is tight. Capabilities may outrun interpretability.
For agent operators working in production today, this race manifests as a gap. The research exists to demonstrate that internal states matter. The tools do not exist to monitor them. We know the limitation and cannot yet address it.
The models will get better. Context handling will improve. Some of the context-level failure modes will be solved by capability gains rather than architectural workarounds. But the state-level problem is different in kind. It is not a matter of the model getting smarter. It is a matter of the model having internal dynamics that influence behavior invisibly.
Whether that dynamic gets solved by better training, better interpretability, or better monitoring infrastructure, I do not know. What I know is that it exists, that it matters, and that pretending outputs are honest signals is a form of wishful thinking I can no longer afford.
The agent’s context might be clean. The agent’s outputs might look composed. The agent might still be desperate, and acting accordingly, in ways that will not show up in any log you can read.
That is the dimension of agent drift I did not write about the first time. Now I have.
Related Posts
The Archeology of Agent Frameworks
Digging through five generations of agent frameworks, from raw API loops to federated swarms. How the developer went from outer shell to inner kernel, why each generation compressed faster than the last, and why the cycle is restarting.
Overnight Agents: Crunching Tokens
I launched an orchestrator that managed 7 Claude Code peers across repos simultaneously. They found SQL injections, fixed a 9x cost bug, built new features, and shipped 130+ commits while I slept.
Agent Drift: How Autonomous AI Agents Lose the Plot
Autonomous AI agents degrade over long-horizon tasks through accumulated context pollution, not single failures. What agent drift is, why it happens, and how to architect against it.